Building an Encoder-Decoder sequence for image segmentation,That’s to say,I use black background and white foreground to train the whole network.and in test process, it generate nothing but black!
I check the softmax output, find that it does theat the background pixel to 0 channel, so argmax op generate 0 at this pixel.But foreground pixel’s softmax output is even. just(0.5,0.5),so it can’t distinguish,so the argmax chose the natural order 0 to present the class,and generate 0.
So when I use armax it generate all black image, and the argmin to distinguish the background , but at these even pixel,the network fails.
but at these even pixel,the network fails.
I conjecture that I use a different deconv process.Deconvolution and Checkerboard Artifacts that’s which inspire me cause I used to use deconv,but it generate checkerboard inside the white area.so I follow the blog to use upsampling layer and a size-keeping conv operation to replace the deconv layer.But it fails,too.WHERE to modify?I really confused, and, a bit upset.
new user only one pic one topic? sry for being a freshman with no privilege.
As far as I understand your problem, you’ve changed your model architecture because of the checkerboard artifacts, and your new model is not learning anything useful now.
Is this correct?
Do you have just this single image? If not, how many images are in your training, validation and test set?
Could you observe the losses for the separate datasets?
Is the training loss going down at all?
yeah,after conjecture and observe many times, I argue that the network is able to catogorize those background pixel to the background,but unable to distinguish pixel inside the foreground area,I really don’t know why.
the new model is totally re-initlialized so it descent again, with no memory about the old model.
I split the dataset into train/test by 9:1, numerically count 2700:300, and the loss is approaching 0.05,
the old model is approaching 0.019,for those checkerboard artifacts influence the loss descent.
now the new model’s loss is influenced by those even pixels ,they only occur inside the foreground area.now the loss is hardly descent more.
Could you post the (simplified) code, so that we could exclude some coding errors?
As a first step in debugging I could suggest to use only one single training sample and try to overfit your model badly on it. The loss should decrease to zero and the segmentation should look clear.
If that’s not possible, your model or training procedure might have some bugs.
I use a pretrained vgg16, extract the feature maps before the last three pooling layer,and passed through a inception module to fuse the three feature maps to one, them send this output as decoder input, upsampling 3 times to recover to initial size.
U mean use only one pic to train? I used to use 30 pics to train 300 epoches ,but just generate a black-white pic like a heatmap, with no obvious shape, just like a scattering plot.and the loss seems convere at 0.3 when 30/300, what a early converge! then it fluctuates, no more obvious change.
Yeah, I use one sample to train and test, it generate great result on it .the result are nearly identical to the origin segmentation result, so i argue that the network architecture has the capacity to do this work, but I still don’t know the reason.seems badly overfitting, but the loss ,numerically so high.initial loss is 0.75, after 400 epoches is 0.22
That’s a good sign!
Have you tried to change the learning rate and see, how the loss behaves?
trained with SGD, lr=1e-3,momentum =0.9, weight-decay=1e-6, I’ll do as your said,to see if the loss are descenting to zero after so many epoches.(I set to 5000,usually 200 to show a good result)
after 5000 epoches ,I can see no more difference between the result and origin mask, loss reaches 0.02,so what’s that mean? can I use this architecture and hyperparameter safe?with no modification? to train the whole training set?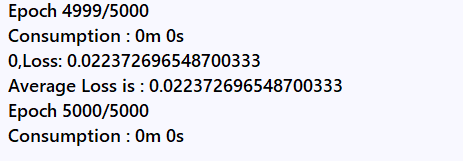
What kind of loss are you using? NLLLoss?
What are your output and target shapes?
Could you have a look at the error image ((prediction - target).abs())?
Do you see some errors at specific regions, e.g. corners?
yeah, the NLL_Loss
output:2x640x480
target:640x480
I follow the guidance of official documentation, output should have :NCHW,target:NHW, I conjecture that’s because the target use pixel-wise class label for calculation.
specificly, I use loss=functional.nll_loss(functional.log_softmax(segmap,dim=1),mask)
this to calculate
the output is .jpg and target is bmp file.
seems not good ![]()
Yes, the shapes are correct.
Well that’s more or less the simplest approach for the model and the result doesn’t seem to be that good.
Using this approach your prediction on the whole set will probably be worse than this.
I would suggest to try to change the hyperparameters (e.g. learning rate, weight init, optimizer etc.) and to push the loss close to zero so that the single sample will look almost like the ground truth.
I use lr 1e-3 ,SGD with 10 batch size,weight init follows the xavier_normal and bias sets to 0.
Are there any other hyperparameter solution from ur perspective,or emperically setting? the loss reaches 0.049 for best ever.but it seems still too high.
At first I would try to overfit the single sample, so the batch size shouldn’t matter.
I would try to use Adam with an initial lr=1e-3 and xavier_uniform for the weights.
If your model never reaches a nearly perfect solution, you might want to add some capacity to it, i.e. making the layers bigger.
Thx! Another question:If the output and target seems identical, at least from my perspective,why the abs op create such an obvious contour with scattered point? and what is the modification: make the layer bigger mean?
mask

result

Did you subtract the prediction, i.e. the binary image, from the target or the probabilities?
Could you check the min and max of the error image?
Maybe the range is quite low, but your plot lib has scaled it up?
the target and pred are all range from 0 to 255.I use the channel-wise argmax op to generate the pred ndarray,and then times 255 cause the label is 0 or 1, so times 255 to make it show as an image in black and white.

that’s the result follow ur guidance.
Thanks for the update. Could you post some stats using
print(np.unique(x, return_counts=True))
This will return the different error values and their count in the image.
Maybe most of the errors are just really small and just very few errors are large.
I just did the work. convert the non-zero part to a set and then sort it

and I 'm wondering if the two images are 0 1 based, why their subtraction can generate digit out of 0 1?
In my thought ,the argmax can generate image with channel label ,so it should be 0 or 1.the target,it still 0 or 1(I use cv2.imread to read pic as a ndarray, and do torchvision.ToTensor directly, cause seems it transform the [0,255] to [0.0,1.0])
so the target and pred all consist of 0 or 1, can they generate other digit?
I’m wondering where I went wrong.
