Hi guys, I’m training a graph neural network of the form (Fully connected layers → Message-passing steps → Fully connected layers), and have found that while most of the fully connected layers are learning, the message-passing layers have extremely low gradient.
I thought this might be a case of the vanishing gradient problem, though I’m not sure since the fully-connected layers before the message-passing layers are learning and have non-zero gradient.
I discovered the issue by looking at the Weights&Biases parameter/gradient visualization, and found that the gradients on the message-passing layers were all close to zero. As a result, the parameters barely shift from their initial values.
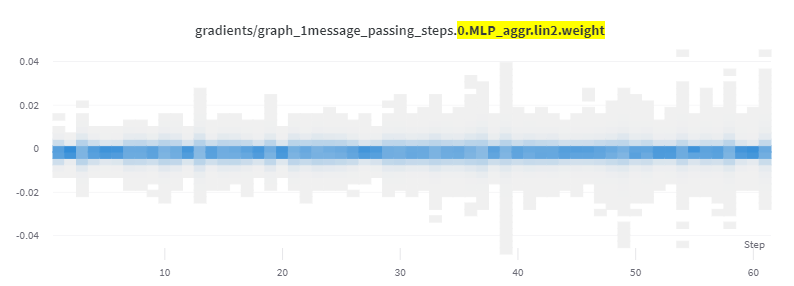
Note in the below images that the first set’s gradient values are an order of magnitude lower than the second.
Gradient values in one of the linear layers in the first message-passing layer:
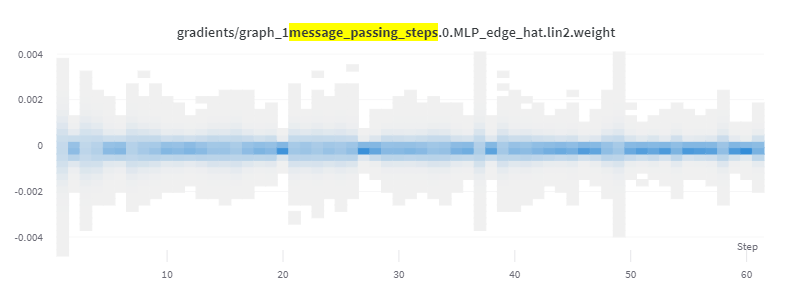
Resulting parameter distribution:
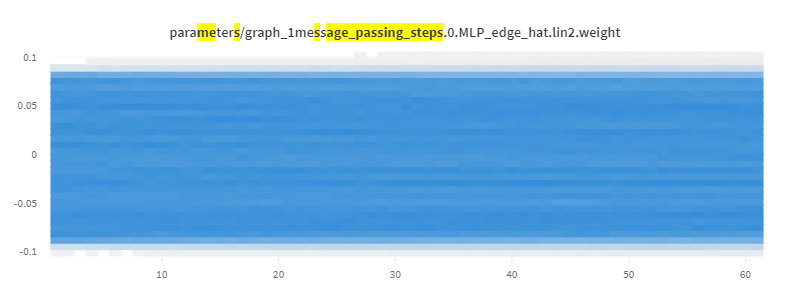
Gradient values in first fully-connected layer of network:
Resulting parameter distribution:
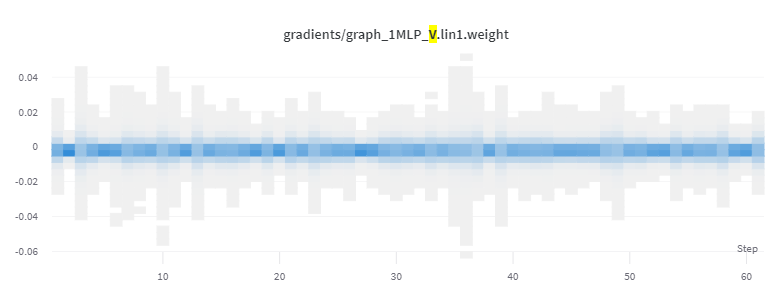
However, some layers in the message-passing steps do seem to learn. Here’s one which has higher gradient values:
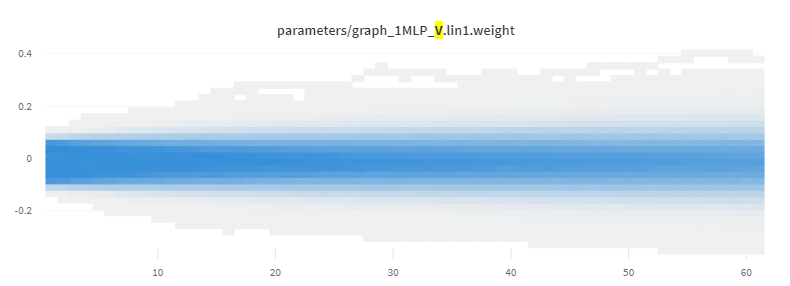
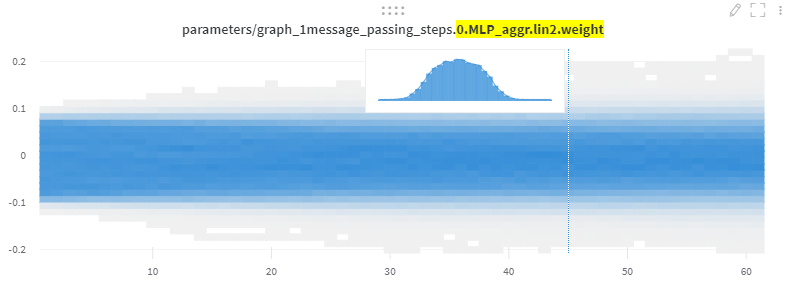
Resulting parameter distribution:
Does anyone have a clue as to what might be going on here? Why would the gradient values at some of the layers of the message-passing nn be so low?
I am training using SGD with LR=0.01, momentum=0.8, dropout=0.5 after all message-passing fully-connected layers. To code the graph neural-network, I am using PyTorch Geometric.