UPDATE: I was able to get things working, and got the following output using some convolutional ResNet layers, averaged, for the target layers. The critical mistakes I had made were (1) not turning on gradients for all layers (I had frozen the backbone for transfer learning), and (2) not running a fwd and bkwd pass on the freshly reloaded model to make sure there were gradients cached. It seems that grad-CAM does not work without these things (seems “duh!” in retrospect)— the error message was unfortunately not especially helpful.
I am still looking for input from those who are familiar with grad-CAM on whether my layer selections are sensible etc.! I just found out about grad-CAM today and did not have time to read through the full research paper yet, so while I understand the general concept of interpreting gradients as ‘importance’ and mapping this back to the input space, the math is wishy-washy for me.
Output:
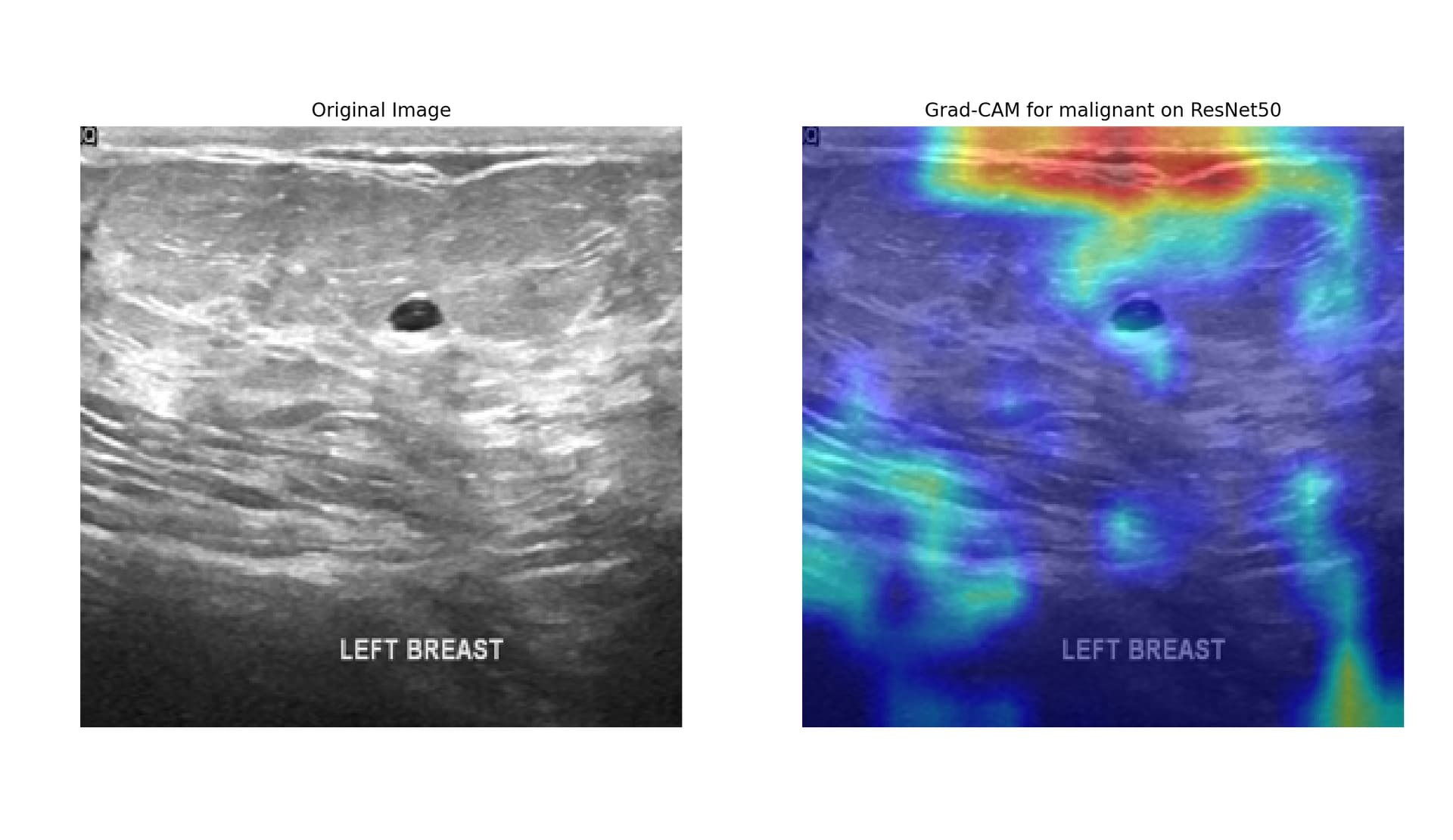
Working Code:
"""
Qualitative model interpretability using Grad-CAM and friends.
for the inspiration.
"""
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms, models
from PIL import Image
import numpy as np
import os
from argparse import Namespace
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
from matplotlib import pyplot as plt
from src.model import load_model
from src.util import validate_args
from src.data import CaffeTransform
import argparse
def load_image(image_path: str, device, args):
transform = transforms.Compose(
[
transforms.Resize((args.image_size, args.image_size)),
transforms.ToTensor(),
CaffeTransform(),
transforms.Normalize(mean=[0, 0, 0], std=[0.225, 0.224, 0.229]),
]
)
image = Image.open(image_path).convert("RGB") # Convert to RGB
image = transform(image).unsqueeze(0).to(device)
return image
def visualize_image_with_gradcam(image_index: int, args, device):
"""
Use Grad-CAM to visualize importance of input image regions for img {image_index}
in the dataset for the specified task and using the model with the specified
hyperparameters.
Hyperparameters and task defined in args.
"""
data_path = f"./data/{args.data_dir}/images"
model_dir = f"./data/{args.data_dir}/models"
model_name = f"best_model_{args.data_dir}_backbone_{args.backbone_model_name}_clf_{args.clf}_fold_{args.fold}_structure_{args.structure}_lr_{args.lr}_batchsize_{args.batch_size}_dropprob_{args.dropout_prob}_fcsizeratio_{args.fc_hidden_size_ratio}_numfilters_{args.num_filters}_kernelsize_{args.kernel_size}_epochs_{args.epoch}.pth"
model_path = os.path.join(model_dir, model_name)
assert os.path.exists(model_path), f"Model weights not found at {model_path}"
checkpoint = torch.load(model_path, map_location=device)
model_state_dict = checkpoint["model_state_dict"]
# ==== load in model and img ======
model = load_model(device, args)
print("======= Model Loaded ======")
# for name, layer in model.named_children():
# print(f"{name}: {layer}")
print("===========================")
model.load_state_dict(model_state_dict)
model.eval() # Set model to evaluation mode
# !!! enable gradients. Essential to re-enable gradient flow when
# transfer learning on a frozen backbone
for param in model.parameters():
param.requires_grad = True
image_files = sorted(os.listdir(data_path))
image_path = os.path.join(data_path, image_files[image_index])
input_tensor = load_image(image_path, device, args)
input_tensor.requires_grad = True
# Set target layers for Grad-CAM
target_layers = []
if args.backbone_model_name.startswith("DenseNet"):
target_layers += [model.backbone.backbone[-1]] # Last layer of DenseNet
elif args.backbone_model_name.startswith("ResNet"):
# Last few layers of ResNet
resnet_layers = list(model.backbone.backbone.children())
target_layers += [
resnet_layers[-3],
resnet_layers[-2],
] # avg. a few of the late resnet !convolutional! layers (the last layer is useless avg pool)
else:
raise ValueError("Unsupported model backbone")
# Add a layer from the classifier (if it has more than one layer)
classifier_layers = list(model.classifier.children())
if len(classifier_layers) > 1:
target_layers += [classifier_layers[-1]]
positive_class = "malignant" if args.data_dir == "breast" else "yes"
class_idx = 1 # Assuming positive class is the second class
# fwd pass and backward pass to get the outputs and calculate gradients for Grad-CAM
# !!! Don't be dumb and not compute gradients like me
output = model(input_tensor)
loss = nn.CrossEntropyLoss()(output, torch.tensor([class_idx]).to(device))
model.zero_grad()
loss.backward()
# run the grad-CAM algorithm
cam = GradCAM(model=model, target_layers=target_layers)
targets = [ClassifierOutputTarget(class_idx)]
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)[0, :]
if not np.any(grayscale_cam):
print("Warning: Grayscale CAM is all zeros. Check the model and target layers.")
""" debugging: visualize the grayscale cam
print("Grayscale CAM:")
plt.figure(figsize=(10, 10))
plt.imshow(grayscale_cam, cmap='gray')
plt.title(f"Grayscale CAM for {positive_class} on {args.backbone_model_name}")
plt.axis('off')
plt.show()
"""
# visualize grad-CAM heatmap overlayed on the original image
rgb_img = (
np.array(
Image.open(image_path)
.convert("RGB")
.resize((args.image_size, args.image_size))
)
/ 255.0
)
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(rgb_img)
axes[0].set_title("Original Image")
axes[0].axis("off")
axes[1].imshow(visualization)
axes[1].set_title(f"Grad-CAM for {positive_class} on {args.backbone_model_name}")
axes[1].axis("off")
plt.show()
def main():
"""
Run gradcam visualization for request task, image, and args.
Example usage:
python script.py --data_dir acl --database RadImageNet --backbone_model_name DenseNet121 --clf Conv --fold full --structure freezeall --lr 0.0001 --batch_size 128 --dropout_prob 0.5 --fc_hidden_size_ratio 0.5 --num_filters 16 --kernel_size 2 --epoch 5 --image_index 0 --image_size 256
"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--data_dir",
type=str,
required=True,
help="Name of the data directory, e.g., acl",
)
parser.add_argument(
"--database", type=str, required=True, help="Choose RadImageNet or ImageNet"
)
parser.add_argument(
"--backbone_model_name",
type=str,
required=True,
help="Choose ResNet50, DenseNet121, or InceptionV3",
)
parser.add_argument(
"--clf",
type=str,
required=True,
help="Classifier type. Choose Linear, Nonlinear, Conv, or ConvSkip",
)
parser.add_argument("--batch_size", type=int, default=256, help="Batch size")
parser.add_argument("--image_size", type=int, default=256, help="Image size")
parser.add_argument("--epoch", type=int, default=30, help="Number of epochs")
parser.add_argument(
"--structure",
type=str,
default="unfreezeall",
help="Structure: unfreezeall, freezeall, or unfreezetop10",
)
parser.add_argument("--lr", type=float, default=0.001, help="Learning rate")
parser.add_argument(
"--lr_decay_method",
type=str,
default=None,
help=(
"LR Decay Method. Choose from None (default), 'cosine' for Cosine "
"Annealing, 'beta' for multiplying LR by lr_decay_beta each epoch"
),
)
parser.add_argument(
"--lr_decay_beta",
type=float,
default=0.5,
help="Beta for LR Decay. Multiply LR by lr_decay_beta each epoch if lr_decay_method = 'beta'",
)
parser.add_argument(
"--dropout_prob",
type=float,
default=0.5,
help="Prob. of dropping nodes in dropout layers",
)
parser.add_argument(
"--fc_hidden_size_ratio",
type=float,
default=0.5,
help="Ratio of hidden size to features for FC intermediate layers.",
)
parser.add_argument(
"--num_filters",
type=int,
default=4,
help="Number of Filters used in convolutional layers.",
)
parser.add_argument(
"--kernel_size",
type=int,
default=2,
help="Size of Kernel used in convolutional layers.",
)
parser.add_argument(
"--amp",
action="store_true",
help=(
"Enable AMP for faster mixed-precision training. Need CUDA + "
"recommend batch size of 256+ to use throughput gains if running AMP."
),
)
parser.add_argument("--log_every", type=int, default=100)
parser.add_argument(
"--use_folds",
action="store_true",
default=False,
help=(
"Run separate models for different train and validation folds. "
"Useful for matching original RadImageNet baselines, but messy."
),
)
parser.add_argument("--verbose", action="store_true", help="Enable verbose output")
parser.add_argument(
"--image_index", type=int, required=True, help="Index of the image to visualize"
)
parser.add_argument("--fold", type=str, required=True, help="Fold of the model")
args = parser.parse_args()
validate_args(args, verbose=True)
# ====== Set Device, priority cuda > mps > cpu =======
# discard parallelization for now
device = None
if torch.cuda.is_available():
device = torch.device("cuda")
torch.backends.cudnn.benchmark = (
True # Enable cuDNN benchmark for optimal performance
)
torch.backends.cudnn.deterministic = (
False # Set to False to allow for the best performance
)
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
if args.verbose:
print("\n=====================")
print(f"Device Located: {device}")
print(f"Loading data from directory: {args.data_dir}")
print("=====================\n")
visualize_image_with_gradcam(args.image_index, args, device)
if __name__ == "__main__":
main()
ORIGINAL POST:
I cannot seem to get Grad-CAM working based on the repo: GitHub - jacobgil/pytorch-grad-cam: Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more.
I have a sequential model consisting of a backbone (ResNet50 or DenseNet121, with their last layer chopped off so that they are now feature-extractors), followed by a classifier (the classifier varies). I load in the model, load a state dict of my best model from training, and my goal is to visualize an image from the dataset and the importance of the input image regions on the prediction using Grad-CAM. I figure the target layer should be the last layer of the backbone, as that is the feature layer = the penultimate layer of the original backbone models.
However, when I try to implement this, the grads variable handled internally is set to None, which of course means that Grad-CAM completely fails since I have no gradients. I am quite confused as I couldn’t find this exact issue elsewhere online and the repo seemed quite straightforward. I must be doing something really silly, but I am completely stuck.
My code:
"""
Qualitative model interpretability using Grad-CAM and friends.
See: https://github.com/jacobgil/pytorch-grad-cam
and: https://arxiv.org/abs/1610.02391
for the inspiration.
"""
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms, models
from PIL import Image
import numpy as np
import os
from argparse import Namespace
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
from matplotlib import pyplot as plt
from src.model import load_model
from src.util import validate_args
from src.data import CaffeTransform
import argparse
def load_image(image_path: str, device, args):
transform = transforms.Compose([
transforms.Resize((args.image_size, args.image_size)),
transforms.ToTensor(),
CaffeTransform(),
transforms.Normalize(mean=[0, 0, 0], std=[0.225, 0.224, 0.229])
])
image = Image.open(image_path).convert('RGB') # Convert to RGB
image = transform(image).unsqueeze(0).to(device)
return image
def visualize_image_with_gradcam(image_index: int, args, device):
"""
Use Grad-CAM to visualize importance of input image regions for img {image_index}
in the dataset for the specified task and using the model with the specified
hyperparameters.
Hyperparameters and task defined in args.
"""
data_path = f"./data/{args.data_dir}/images"
model_dir = f"./data/{args.data_dir}/models"
model_name = f"best_model_{args.data_dir}_backbone_{args.backbone_model_name}_clf_{args.clf}_fold_{args.fold}_structure_{args.structure}_lr_{args.lr}_batchsize_{args.batch_size}_dropprob_{args.dropout_prob}_fcsizeratio_{args.fc_hidden_size_ratio}_numfilters_{args.num_filters}_kernelsize_{args.kernel_size}_epochs_{args.epoch}.pth"
model_path = os.path.join(model_dir, model_name)
assert os.path.exists(model_path), f"Model weights not found at {model_path}"
checkpoint = torch.load(model_path, map_location=device)
model_state_dict = checkpoint['model_state_dict']
# ==== load in model and img ======
model = load_model(device, args)
print("======= Model Loaded ======")
for name, layer in model.named_children():
print(f"{name}: {layer}")
print("===========================")
model.load_state_dict(model_state_dict)
image_files = sorted(os.listdir(data_path))
image_path = os.path.join(data_path, image_files[image_index])
input_tensor = load_image(image_path, device, args)
# ===== set target layer and perform grad-CAM for the positive class ======
# These are the suggested Grad-CAM target layers for these two architectures
# based on: https://github.com/jacobgil/pytorch-grad-cam
# use the feature extraction layer, not the classifier
# classifier just affects the gradients for the particular positive class
# through this feature layer. TODO: I want to better understand the math
if args.backbone_model_name.startswith("DenseNet"):
backbone = model[0]
target_layers = [*list(backbone.children())[-1]] # model is a Sequential with DenseNet as the first part
elif args.backbone_model_name.startswith("ResNet"):
backbone = model[0]
target_layers = [*list(backbone.children())[-1]] # model is a Sequential with ResNet as the first part
else:
raise ValueError("Unsupported model backbone")
positive_class = 'malignant' if args.data_dir == 'breast' else 'yes'
class_idx = 1 # Assuming positive class is the second class
cam = GradCAM(model=model, target_layers=target_layers)
targets = [ClassifierOutputTarget(class_idx)]
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)[0, :]
# ===== visualize the grad CAM results ======
rgb_img = np.array(Image.open(image_path).convert('RGB').resize((args.image_size, args.image_size))) / 255.0
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
plt.figure(figsize=(10, 10))
plt.imshow(visualization)
plt.title(f"Grad-CAM for {positive_class} on {args.backbone_model_name}")
plt.axis('off')
plt.show()
def main():
"""
Run gradcam visualization for request task, image, and args.
Example usage:
python script.py --data_dir acl --database RadImageNet --backbone_model_name DenseNet121 --clf Conv --fold full --structure freezeall --lr 0.0001 --batch_size 128 --dropout_prob 0.5 --fc_hidden_size_ratio 0.5 --num_filters 16 --kernel_size 2 --epoch 5 --image_index 0 --image_size 256
"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--data_dir",
type=str,
required=True,
help="Name of the data directory, e.g., acl",
)
parser.add_argument(
"--database", type=str, required=True, help="Choose RadImageNet or ImageNet"
)
parser.add_argument(
"--backbone_model_name",
type=str, required=True,
help="Choose ResNet50, DenseNet121, or InceptionV3",
)
parser.add_argument(
"--clf",
type=str, required=True,
help="Classifier type. Choose Linear, Nonlinear, Conv, or ConvSkip",
)
parser.add_argument("--batch_size", type=int, default=256, help="Batch size")
parser.add_argument("--image_size", type=int, default=256, help="Image size")
parser.add_argument("--epoch", type=int, default=30, help="Number of epochs")
parser.add_argument(
"--structure",
type=str, default="unfreezeall",
help="Structure: unfreezeall, freezeall, or unfreezetop10",
)
parser.add_argument("--lr", type=float, default=0.001, help="Learning rate")
parser.add_argument(
"--lr_decay_method",
type=str, default=None,
help=(
"LR Decay Method. Choose from None (default), 'cosine' for Cosine "
"Annealing, 'beta' for multiplying LR by lr_decay_beta each epoch"
),
)
parser.add_argument(
"--lr_decay_beta",
type=float, default=0.5,
help="Beta for LR Decay. Multiply LR by lr_decay_beta each epoch if lr_decay_method = 'beta'",
)
parser.add_argument(
"--dropout_prob",
type=float, default=0.5,
help="Prob. of dropping nodes in dropout layers",
)
parser.add_argument(
"--fc_hidden_size_ratio",
type=float, default=0.5,
help="Ratio of hidden size to features for FC intermediate layers.",
)
parser.add_argument(
"--num_filters",
type=int, default=4,
help="Number of Filters used in convolutional layers.",
)
parser.add_argument(
"--kernel_size",
type=int, default=2,
help="Size of Kernel used in convolutional layers.",
)
parser.add_argument(
"--amp",
action="store_true",
help=(
"Enable AMP for faster mixed-precision training. Need CUDA + "
"recommend batch size of 256+ to use throughput gains if running AMP."
),
)
parser.add_argument("--log_every", type=int, default=100)
parser.add_argument(
"--use_folds",
action="store_true",
default=False,
help=(
"Run separate models for different train and validation folds. "
"Useful for matching original RadImageNet baselines, but messy."
),
)
parser.add_argument("--verbose", action="store_true", help="Enable verbose output")
parser.add_argument("--image_index", type=int, required=True, help="Index of the image to visualize")
parser.add_argument("--fold", type=str, required=True, help="Fold of the model")
args = parser.parse_args()
validate_args(args, verbose=True)
# ====== Set Device, priority cuda > mps > cpu =======
# discard parallelization for now
device = None
if torch.cuda.is_available():
device = torch.device("cuda")
torch.backends.cudnn.benchmark = (
True # Enable cuDNN benchmark for optimal performance
)
torch.backends.cudnn.deterministic = (
False # Set to False to allow for the best performance
)
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
if args.verbose:
print("\n=====================")
print(f"Device Located: {device}")
print(f"Loading data from directory: {args.data_dir}")
print("=====================\n")
visualize_image_with_gradcam(args.image_index, args, device)
if __name__ == "__main__":
main()
My Error:
===========================
Traceback (most recent call last):
File "/Users/danielfrees/Desktop/RadImageNet/interpret.py", line 223, in <module>
main()
File "/Users/danielfrees/Desktop/RadImageNet/interpret.py", line 220, in main
visualize_image_with_gradcam(args.image_index, args, device)
File "/Users/danielfrees/Desktop/RadImageNet/interpret.py", line 90, in visualize_image_with_gradcam
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)[0, :]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielfrees/miniconda3/envs/cs231/lib/python3.11/site-packages/pytorch_grad_cam/base_cam.py", line 186, in __call__
return self.forward(input_tensor, targets, eigen_smooth)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielfrees/miniconda3/envs/cs231/lib/python3.11/site-packages/pytorch_grad_cam/base_cam.py", line 110, in forward
cam_per_layer = self.compute_cam_per_layer(input_tensor, targets, eigen_smooth)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielfrees/miniconda3/envs/cs231/lib/python3.11/site-packages/pytorch_grad_cam/base_cam.py", line 141, in compute_cam_per_layer
cam = self.get_cam_image(input_tensor, target_layer, targets, layer_activations, layer_grads, eigen_smooth)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielfrees/miniconda3/envs/cs231/lib/python3.11/site-packages/pytorch_grad_cam/base_cam.py", line 66, in get_cam_image
weights = self.get_cam_weights(input_tensor, target_layer, targets, activations, grads)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/danielfrees/miniconda3/envs/cs231/lib/python3.11/site-packages/pytorch_grad_cam/grad_cam.py", line 23, in get_cam_weights
if len(grads.shape) == 4:
^^^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'shape'
Any help is much appreciated! I apologize if I have missed some PyTorch forums formatting rules as well, this is my first post and I am in a bit of a rush as I’m trying to get this working for an imminent project deadline. Thanks ![]()
Note: I have made sure that my model is being loaded in as expected (nn.Sequential() with ResNet with the last classifier layer chopped off, followed by my customclassifier), so I don’t think my imported src code from other parts of my project is necessary here for debugging.
I also just tried using a custom module inheriting from nn.Module, and this fails the same way that nn.Sequential() did.