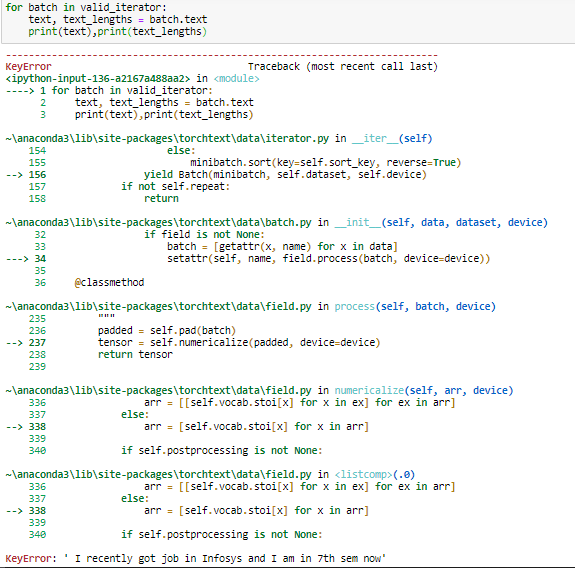
I am facing an issue while using BucketIterator. Below is a code snippet to divide the data into the train and validation set. I am able to iterate the training data but getting the error in the validation dataset. I have tried different seed to check if there is any issue in the data but couldn’t resolve.
Based on the error message it seems the validation dataset cannot load a specific sample due to a KeyError.
You could check the index of the failing sample via:
for idx, batch in enumerate(valid_iterator):
print(idx)
text, text_lengths = batch.text
and based on this index check why this sample is failing to load.
Hello @ptrblck, Thankyou for responding.
I have tried using your snippet.
I don’t think its a data issue as I have changes seeds and split_ratio.
Always, the error is in the validation set.
If there had been an issue in data then I guess train_iterator would also throw an error but train_iterator runs perfectly well.
This One actually worked.
It seems like while using torchtext data split for different build_vocabs, the valid vocab doesn’t seem to have an index located, even after using Glove Embeddings.
I was getting various key errors and then realized this could be one of the issues.