Hi,
I found Categorical cross-entropy loss in Theano and Keras. Is nn.CrossEntropyLoss() equivalent of this loss function?
I saw this topic but three is not a solution for that.
nn.CrossEntropyLoss is used for a multi-class classification or segmentation using categorical labels.
I’m not completely sure, what use cases Keras’ categorical cross-entropy includes, but based on the name I would assume, it’s the same.
Maybe let’s start from your use case and chose the corresponding loss function, so could you explain a bit what you are working on?
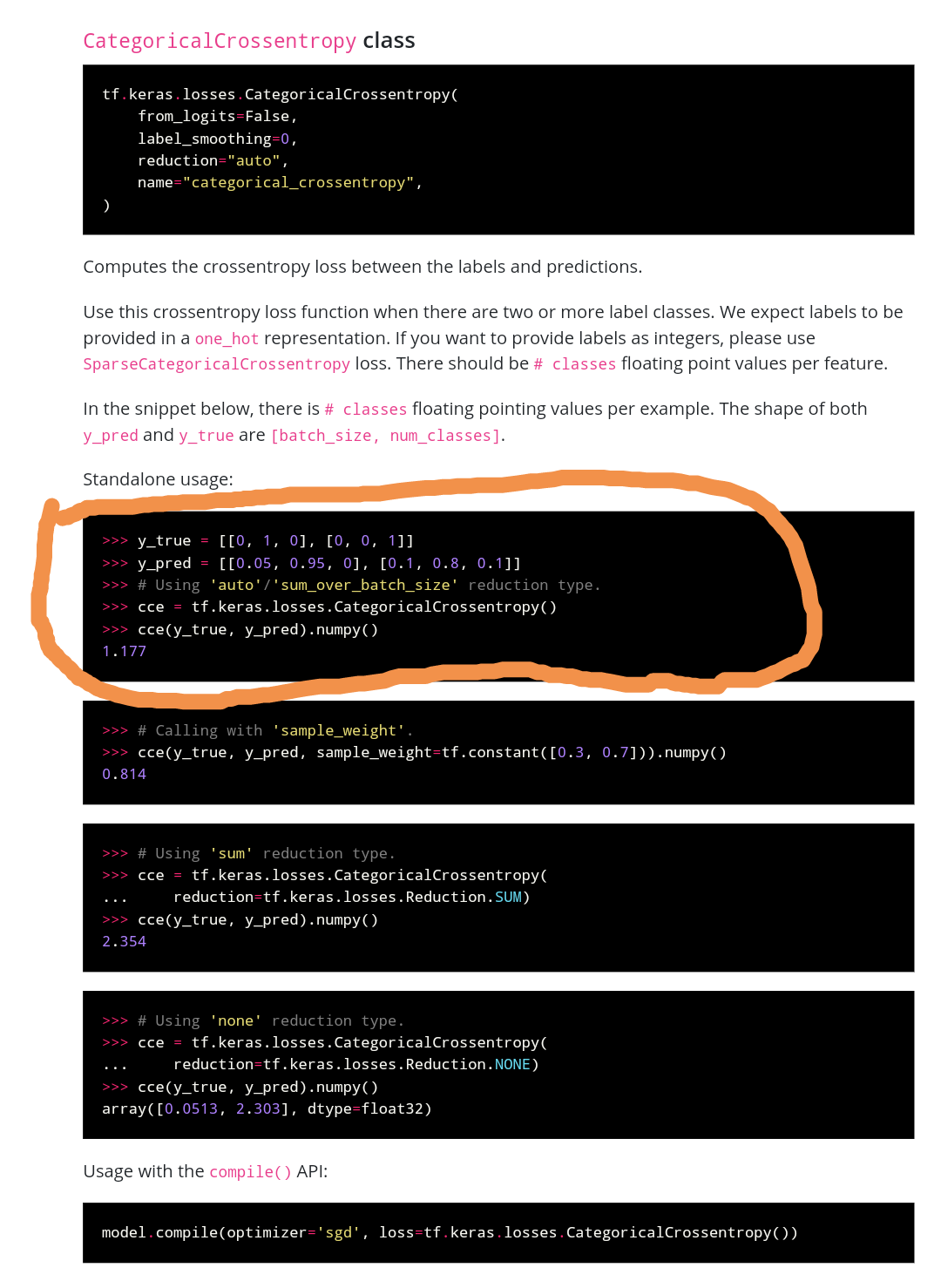

No. Categorical crossentropy (cce) loss in TF is not equivalent to cce loss in PyTorch.
The problem is that there are multiple ways to define cce and TF and PyTorch does it differently.
I haven’t found any builtin PyTorch function that does cce in the way TF does it, but you can easily piece it together yourself:
>>> y_pred = torch.tensor([[0.05, 0.95, 0], [0.1, 0.8, 0.1]])
>>> y_true = torch.tensor([1, 2])
>>> nn.NLLLoss()(torch.log(y_pred), y_true)
tensor(1.1769)
The labels in y_true corresponds to TF’s one-hot encoding.
What is the difference between these implementations besides the target shape (one-hot vs. class index), i.e. do you get different losses for the same inputs?
a bit late but I was trying to understand how Pytorch loss work and came across this post, on the other hand the difference is Simply:
-
categorical_crossentropy(cce) produces a one-hot array containing the probable match for each category, -
sparse_categorical_crossentropy(scce) produces a category index of the most likely matching category. I think this is the one used by Pytroch
Consider a classification problem with 5 categories (or classes).
- In the case of
cce, the one-hot target may be[0, 1, 0, 0, 0]and the model may predict[.2, .5, .1, .1, .1](probably right) - In the case of
scce, the target index may be [1] and the model may predict: [.5].
Consider now a classification problem with 3 classes.
- In the case of
cce, the one-hot target might be[0, 0, 1]and the model may predict[.5, .1, .4](probably inaccurate, given that it gives more probability to the first class) - In the case of
scce, the target index might be[0], and the model may predict[.5]
Many categorical models produce scce output because you save space, but lose A LOT of information (for example, in the 2nd example, index 2 was also very close.) I generally prefer cce output for model reliability.
There are a number of situations to use scce, including:
- when your classes are mutually exclusive, i.e. you don’t care at all about other close-enough predictions,
- the number of categories is large to the prediction output becomes overwhelming.
(-pred_label.log() * target_label).sum(dim=1).mean()
(-(pred_label+1e-5).log() * target_label).sum(dim=1).mean()
This has also been adressed in the commens on stackoverflow but this answer is not correct. The behavioral difference of cce and scce in tensorflow is that cce expectes the target labels as one-hot encoded and scce as class label (single integer).
After a few hours of playing around, please see the following:
import tensorflow as tf
import torch
# Shape: (B, C)
y_true: torch.Tensor
y_pred: torch.Tensor
# All the below are equivalent
# Assumption: model outputs scores (not a Softmax or LogSoftmax)
# PyTorch 1.13.1
-(torch.nn.functional.log_softmax(y_pred, dim=1) * y_true).sum(dim=1).mean()
torch.nn.functional.cross_entropy(input=y_pred, target=y_true)
# TensorFlow 2.11.0
tf.reduce_mean(
tf.keras.metrics.categorical_crossentropy(
y_true, torch.nn.functional.softmax(y_pred, dim=1).detach().numpy()
)
)
tf.reduce_mean(
tf.keras.metrics.categorical_crossentropy(
y_true,
torch.nn.functional.log_softmax(y_pred, dim=1).detach().numpy(),
from_logits=True,
)
)