Hi,
I’m working on an adaptation of the pytorch actor_critic_py for an RRBot example within an OpenAI ROS Kinetic Gazebo 7 environment.
def select_action(self, state):
state = torch.from_numpy(state).float()
probs, state_value = self.model(state)
m = Categorical(probs)
action = m.sample()
self.model.saved_actions.append(self.saved_action(m.log_prob(action), state_value))
return action.item()
At some point, either during initialization or when the RRBot swing up task is approximately in this state during simulation:
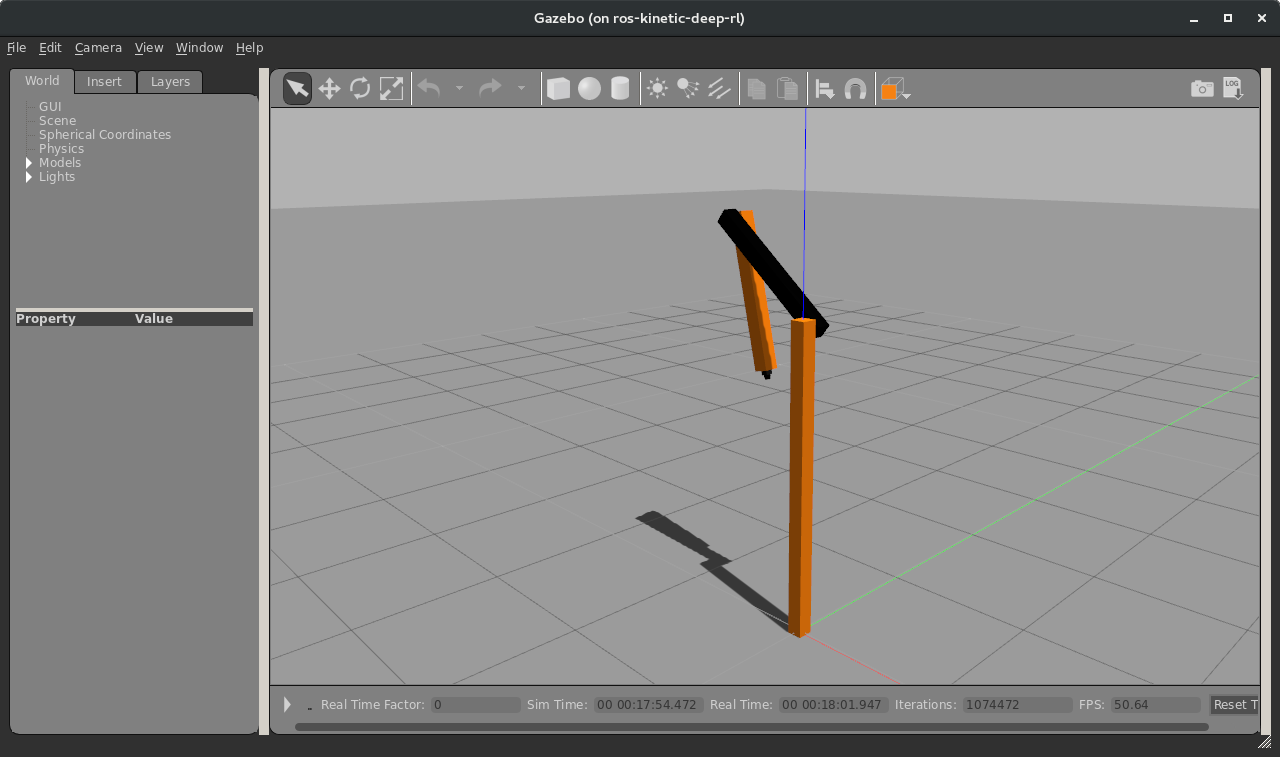
I consistently get the following run-time error:
[WARN] [1539704325.305267, 1074.472000]: PUBLISHING REWARD...
[WARN] [1539704325.305413, 1074.472000]: PUBLISHING REWARD...DONE=0.0,EP=13
Traceback (most recent call last):
File "/project/ros-kinetic-deep-rl/catkin_ws/src/rrbot_openai_ros_tutorial/src/rrbot_v0_start_training_actor_critic.py", line 204, in <module>
main()
File "/project/ros-kinetic-deep-rl/catkin_ws/src/rrbot_openai_ros_tutorial/src/rrbot_v0_start_training_actor_critic.py", line 125, in main
action = agent.select_action(state)
File "/project/ros-kinetic-deep-rl/catkin_ws/src/rrbot_openai_ros_tutorial/src/rrbot_v0_start_training_actor_critic.py", line 64, in select_action
action = m.sample()
File "/usr/local/lib/python2.7/dist-packages/torch/distributions/categorical.py", line 110, in sample
sample_2d = torch.multinomial(probs_2d, 1, True)
RuntimeError: invalid argument 2: invalid multinomial distribution (encountering probability entry < 0) at /pytorch/aten/src/TH/generic/THTensorRandom.cpp:297
[DEBUG] [1539704325.306117, 1074.472000]: END Reseting RobotGazeboEnvironment
