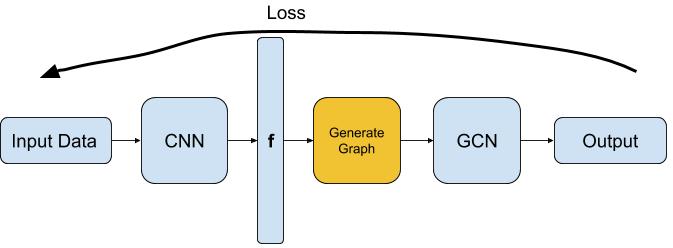
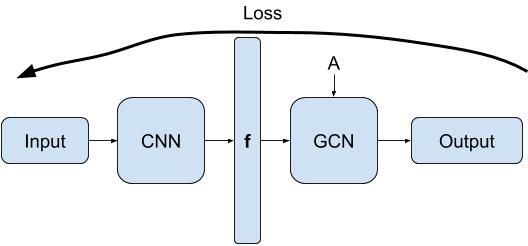
I’m new to pytorch and I would like to design the following model:
“Generate Graph” building block is not part of the network and it just generates a graph using features f every batch. I also want the loss function to be end-to-end.
In fact I know how to design a network with two separate parts (Encoder and GCN) but I cannot connect them together with one loss function with the graph_generator() in between!
Generally, I would like to know how I could change the input of the GCN layer during training. I have a GCN(nn.Module) class that inputs a feature matrix, X, and an adjacency matrix, A, and I want to either modify X or A in every batch.
And to explain what “Generate Graph” block does: it uses the features generated by the CNN block to generate graph(s) using k-nearest neighbor approach.
You could set the requires_grad attribute of both input to True and pass these parameter to the optimizer.
The first step will make sure, that both inputs get gradients, while the latter would of course optimize them using the current loss.
Did you create the “Generate Graph” block in PyTorch?
If that’s the case and also if you didn’t detach the computation graph, you could train the model end2end.
However, if you’ve used non-differentiable methods inside “Generate Graph” or if you’ve used another library such as numpy, you would have to implement the backward method manually.
That’s exactly my problem. I didn’t create “generate graph” in pytorch, in fact I use an external library for that. So I believe it causes the computational graph to detach as you mentioned.
I think I don’t want the “generate graph” block to be included in the training process (there is nothing to be learned), is that possible?
Yes, that would be possible.
However, would you want to train CNN and f?
If so, that wouldn’t be possible, since the computation graph will be detached by “Generate Graph”.
Yes I want to train CNN. Based on what you suggest I think my option is that I only update the feature matrix in the GCN network and keep the adjacency matrix A fixed.
f = CNN(input)
output = GCN(f, A)
where A is fixed and generated using a pre-processing module. Something like this:
Is this feasible?
Hey @ptrblck
If you don’t mind, I have a follow-up. I am trying to create a GCN model (using dgl with PyTorch backend). Layer 1 (a GraphConv layer) takes as inputs an n x d1 and outputs m x d2. The output of the first layer is then fed to the second layer.
x1 = layer1(f) # f is the original input to layer 1
x2 = layer2(x1) # output of layer 1 is given as input to the layer 2.
I want to make changes to x1 (for instance, update a few rows) before feeding it to the second layer. The current solution I have implemented is as follows -
x1 = layer1(f) # f is the original input to layer 1
y = torch.clone(x1) # since in place update isn't allowed
... # make changes to y
x1 = y # assign y back to x1
x2 = layer2(x1) # output of layer 1 is given as input to the layer 2.
Is this a valid way to do this? Would the backward pass work as expected in this case?