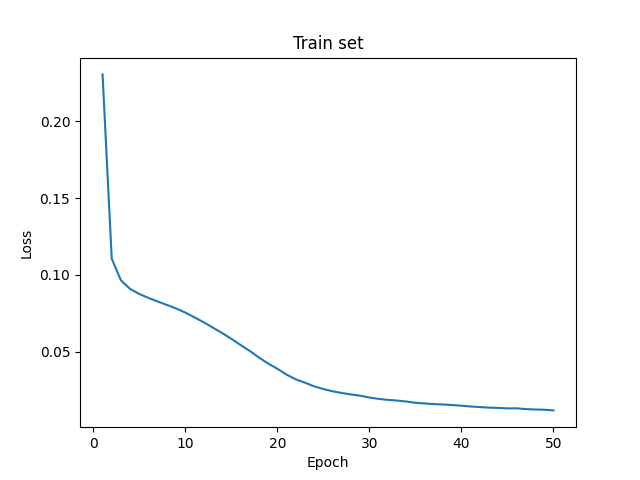
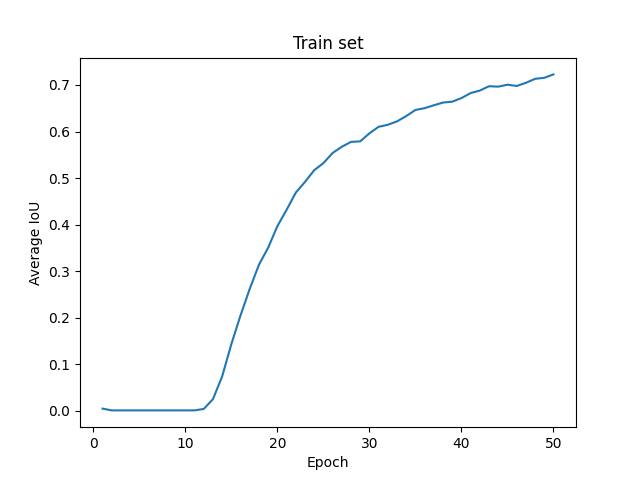
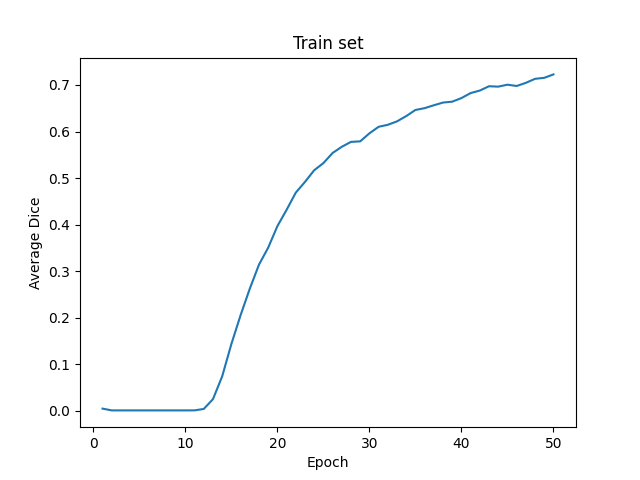
I was just trying to train UNet from scratch with a mammography dataset to detect tumor tissue in mammograms. After training the model for 25 epochs I achieved the following results on TRAIN set:
Epoch 25, Loss: 0.0168, mean_IoU: 0.4271, mean_Dice: 0.3559, Elapsed time: 403.4554 sec
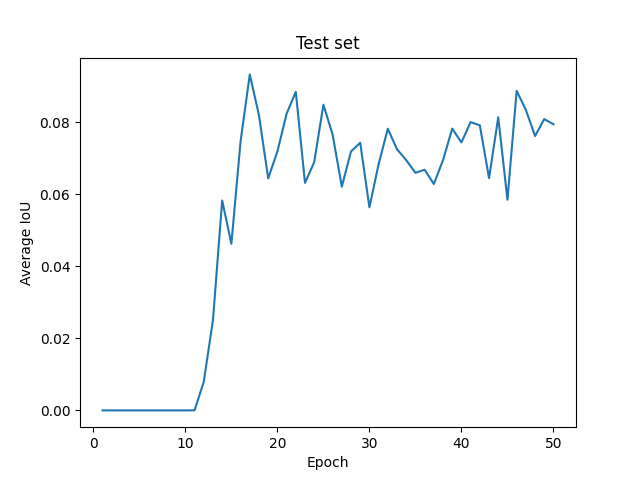
After saving model’s weights and trying to evaluate the model on TEST set, I got a very bad result:
mean_Iou: 0.007, mean_Dice: 0.006
At first, I thought the model is suffering from overfitting, but the model performed badly even on TRAIN set:
mean_Iou: 0.006, mean_Dice: 0.008
The model after loading weights was supposed to reproduce the result in Epoch 25 (am I correct?), but came with very bad results. I doubled check saving and loading model but nothing seems wrong.
Here is the link to implementation on GitHub: GitHub - hrnademi/Mammography
Here is the link to the reported log till epoch 25: Mammography/logs.txt at master · hrnademi/Mammography · GitHub
Further information about the dataset:
Training images: 2400 images with the size of 256x256 png
Test images: 600 images with the size of 256x256 png
In eval.py the pre-trained model is loaded.
Many thanks for your attention.