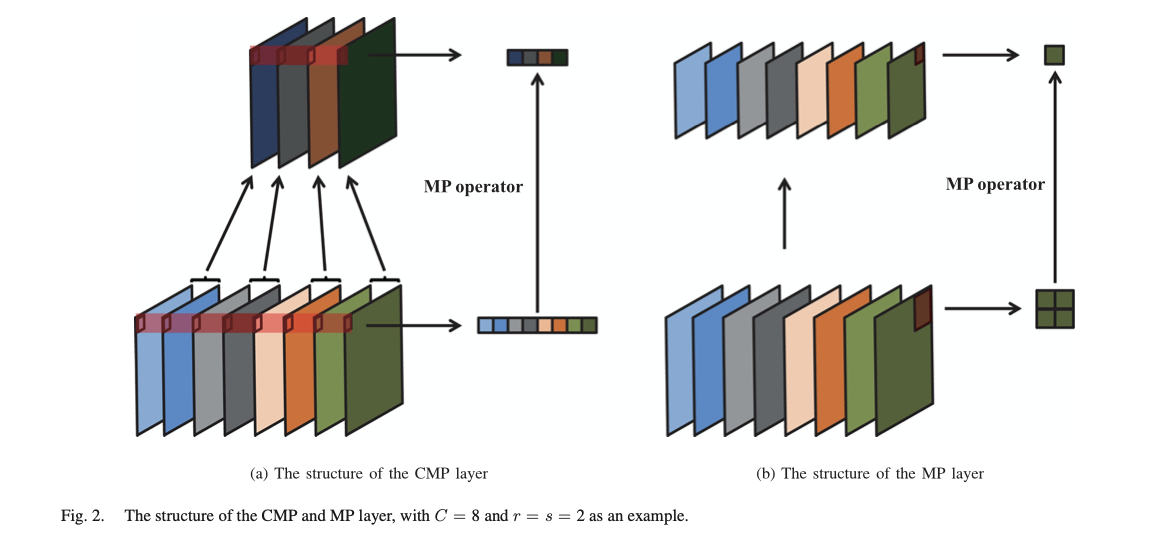
I am trying to replicate a technique from a paper which adds a channel max pooling layer in-between the last max-pooling layer and the first FC layer of the VGG16 model. The paper can be found at https://ieeexplore.ieee.org/document/8648206/citations#citations
You may not be able to read it but the important lines are:
‘VGG16 with CMP (VGG16-CMP): Similar as DenseNet161-CMP, we applied the CMP operation to the VGG16 by implementing the CMP layer between the last max-pooling layer and the first FC layer. The dimension of the pooled features was changed from 512 × 7 × 7 to c × 7 × 7. All the other components remained unchanged’
Notes:
CMP is channel max pooling layer
c is the channel number of the feature maps
Questions
1)From the statement above, is the pooling layer the newly layer addd or the max pooling layer already present?
2) Is the code below even right?
I have created a custom maxpooling layer and added this to the model but I have no clue if it is what the paper is talking about
import torch.nn as nn
import torch
import torchvision
class ChannelPoolingNetwork(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.base = torchvision.models.vgg16(pretrained=True, progress=True)
self.base.features = nn.Sequential(
self.base.features,
ChannelPool(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
print(self.base.features)
self.base.classifier = nn.Sequential(
nn.Linear(25088, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, num_classes)
)
def forward(self, x):
fc = self.base(x)
return fc
# Code from https://stackoverflow.com/questions/46562612/pytorch-maxpooling-over-channels-dimension
class ChannelPool(nn.MaxPool1d):
def forward(self, input):
n, c, w, h = input.size()
input = input.view(n,c,w*h).permute(0,2,1)
pooled = nn.MaxPool1d(input)
_, _, c = input.size()
input = input.permute(0,2,1)
return input.view(n,c,w,h)