I am trying to do semantic segmentation. I have label encoded the rgb masks and hence have a ground truth of shape [batch, height, width].
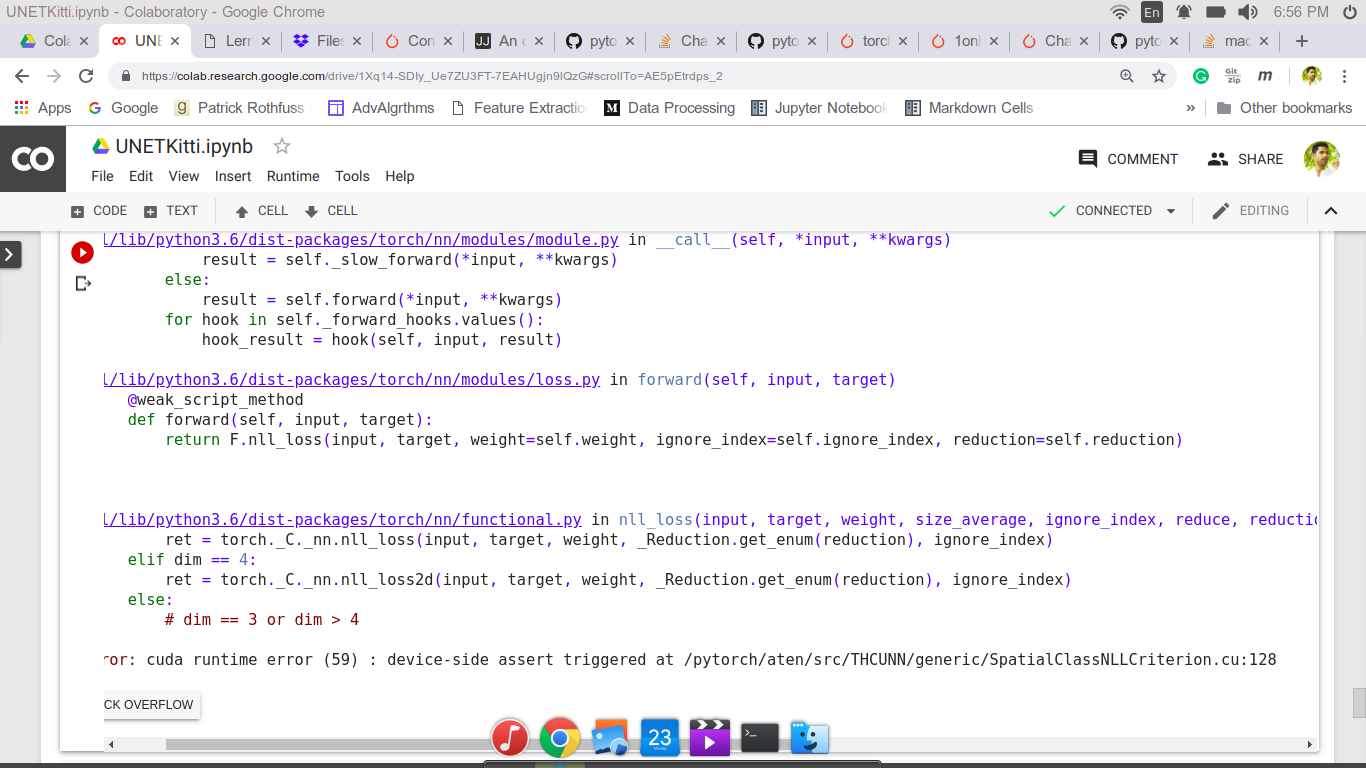
When I try to use cross-entropy loss with my predictions, which are [batch, channels, height, width], I get “cuda runtime error (59) : device-side assert triggered at /pytorch/aten/src/THCUNN/generic/SpatialClassNLLCriterion.cu:128”
You don’t need the channel dimension for the labels. nn.CrossEntropyLoss expects the labels to have the shape [batch_size, height, width] in your semantic segmentation use case, containing class indices.
It looks like you can just pass labels without any modification.
Could you try to run your code on CPU and see, if you get a better error message?
Due to the asynchronous CUDA calls, the stack trace might point to a wrong line of code.
You could also run your code using CUDA_LAUNCH_BLOCKING=1 python script.py args to get a valid stack trace.
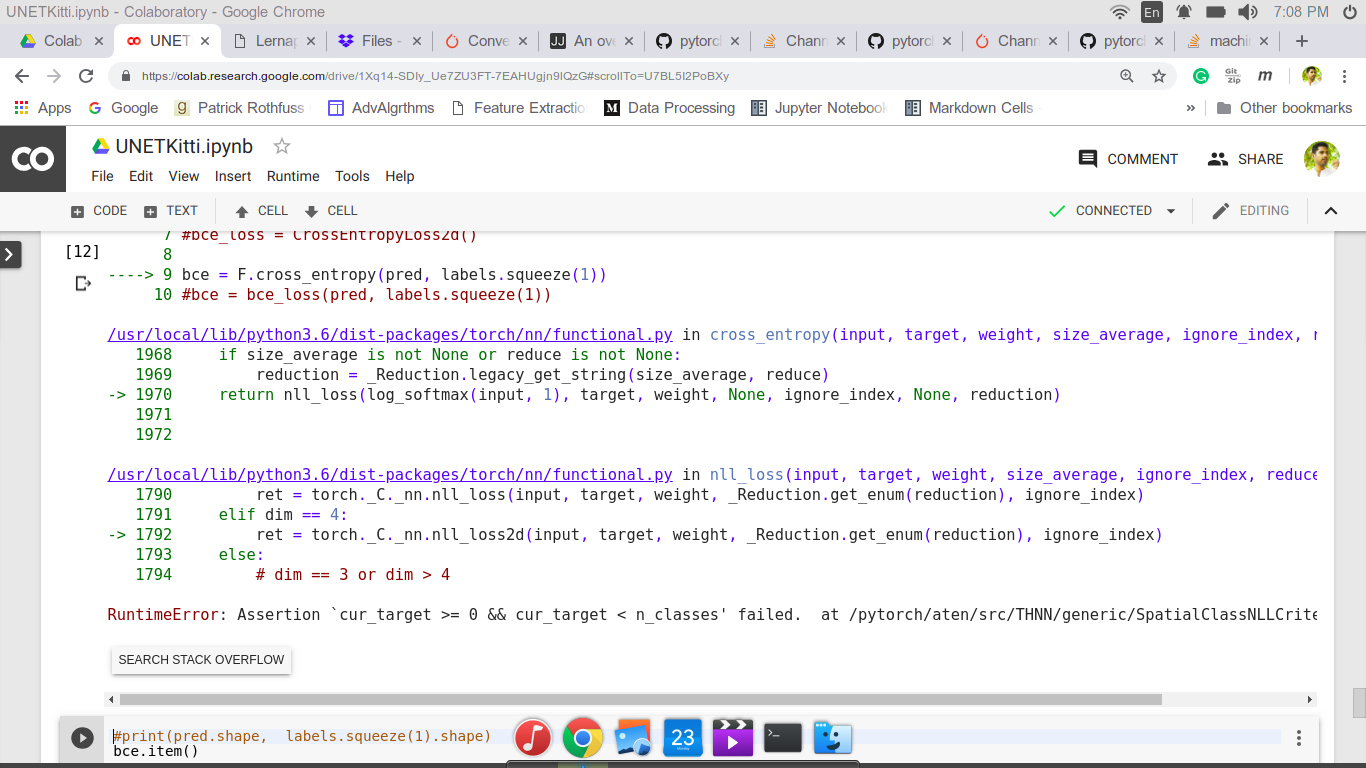
I guess the class indices might be out of bounds, i.e. your labels should contain indices in the range [0, nb_classes-1]. You could add a print statement in your training loop and check the min and max values of your labels.
Thanks for the info. The class indices in labels are indeed out of bounds.
Make sure to only provide labels in the range [0, nb_classes-1]. E.g. if you are dealing with 5 classes for your segmentation task, your labels should only contain the values [0, 1, 2, 3, 4].
Found the issue. The label encoding was perfectly fine. The mistake I was doing was normalising the images using transforms. This was distorting the values.
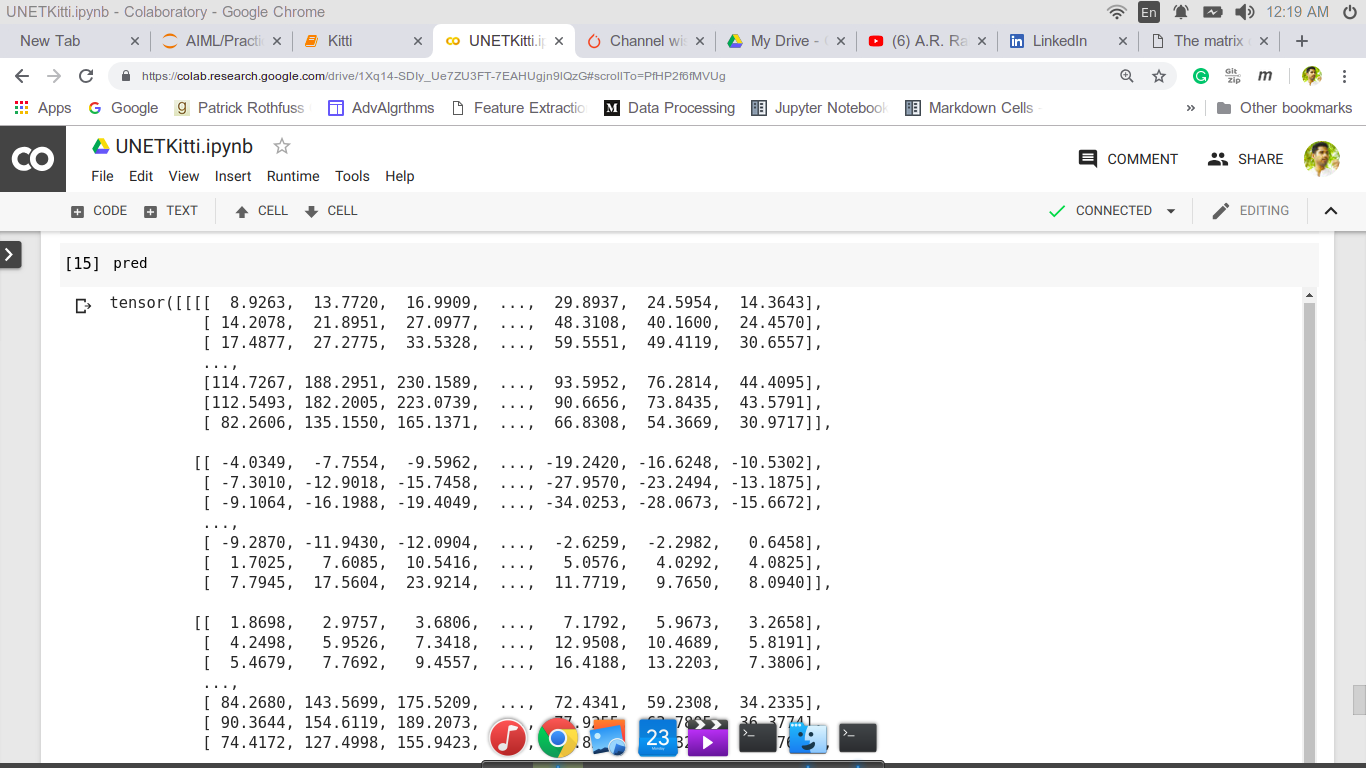
How did you compute pred, as it should contain the class logits without any non-linearity applied onto them.
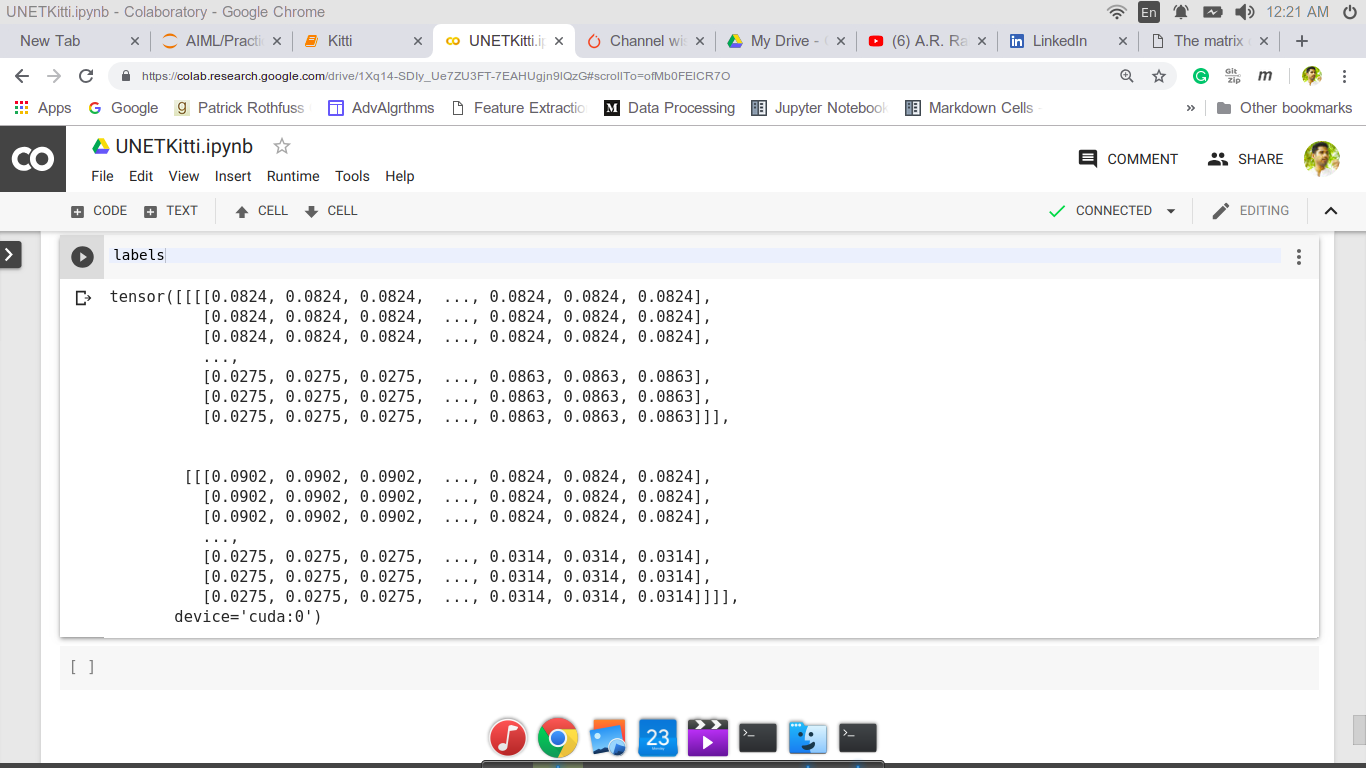
Could you print some samples of pred and labels?
It looks alright, assuming that you rescale your labels to class indices as in torch.long format.
Have you tried to visualize a prediction of your model as a sanity check?
Yeah, It looks sane with some random colors. However, should the loss be 0? the loss begins with 0.2 for the first epoch’s training, but plateaus at 0 during it’s validation phase itself.