Hi,
I’m new to pytorch and have been following the many tutorials available.
But, When I did The CHATBOT TUTORIAL
(Chatbot Tutorial — PyTorch Tutorials 2.9.0+cu128 documentation) is not work.
Like the figure below
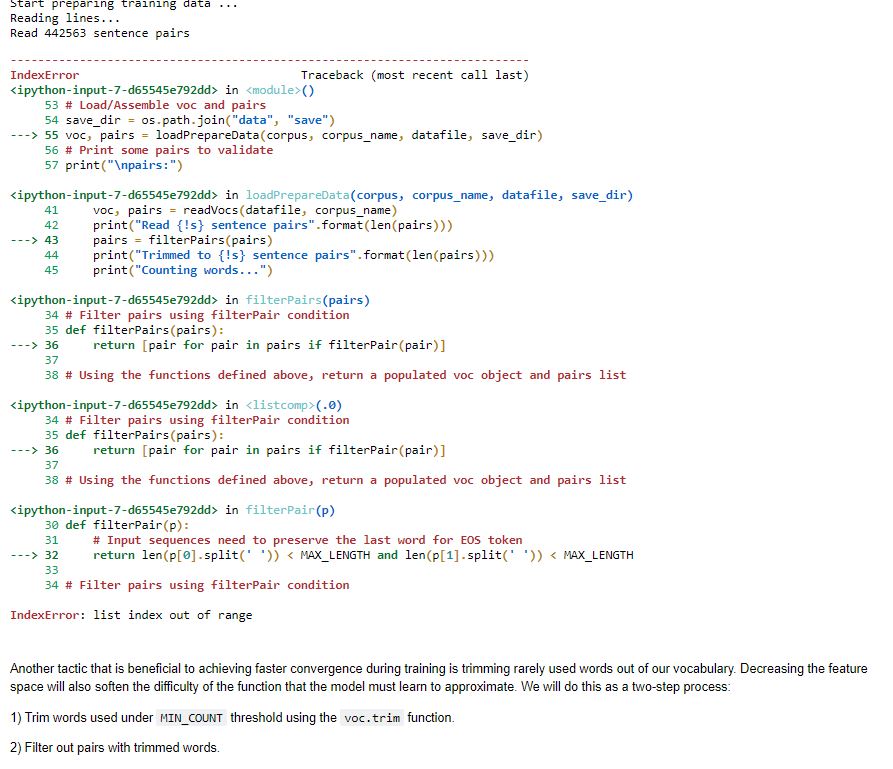
What should I do and what is causing this?
USE_CUDA = torch.cuda.is_available()
device = torch.device(“cuda” if USE_CUDA else “cpu”)
corpus_name = “cornell movie-dialogs corpus”
corpus = os.path.join(“data”, corpus_name)
def printLines(file, n=10):
with open(file, ‘rb’) as datafile:
lines = datafile.readlines()
for line in lines[:n]:
print(line)
#printLines(os.path.join(corpus, “movie_lines.txt”))
Splits each line of the file into a dictionary of fields
def loadLines(fileName, fields):
lines = {}
with open(fileName, ‘r’, encoding=‘iso-8859-1’) as f:
for line in f:
values = line.split(" +++$+++ ")
# Extract fields
lineObj = {}
for i, field in enumerate(fields):
lineObj[field] = values[i]
lines[lineObj[‘lineID’]] = lineObj
return lines
Groups fields of lines from loadLines into conversations based on movie_conversations.txt
def loadConversations(fileName, lines, fields):
conversations =
with open(fileName, ‘r’, encoding=‘iso-8859-1’) as f:
for line in f:
values = line.split(" +++$+++ ")
# Extract fields
convObj = {}
for i, field in enumerate(fields):
convObj[field] = values[i]
# Convert string to list (convObj[“utteranceIDs”] == “[‘L598485’, ‘L598486’, …]”)
lineIds = eval(convObj[“utteranceIDs”])
# Reassemble lines
convObj[“lines”] =
for lineId in lineIds:
convObj[“lines”].append(lines[lineId])
conversations.append(convObj)
return conversations
Extracts pairs of sentences from conversations
def extractSentencePairs(conversations):
qa_pairs =
for conversation in conversations:
# Iterate over all the lines of the conversation
for i in range(len(conversation[“lines”]) - 1): # We ignore the last line (no answer for it)
inputLine = conversation[“lines”][i][“text”].strip()
targetLine = conversation[“lines”][i+1][“text”].strip()
# Filter wrong samples (if one of the lists is empty)
if inputLine and targetLine:
qa_pairs.append([inputLine, targetLine])
return qa_pairs
datafile = os.path.join(corpus, “formatted_movie_lines.txt”)
delimiter = ‘\t’
Unescape the delimiter
delimiter = str(codecs.decode(delimiter, “unicode_escape”))
lines = {}
conversations =
MOVIE_LINES_FIELDS = [“lineID”, “characterID”, “movieID”, “character”, “text”]
MOVIE_CONVERSATIONS_FIELDS = [“character1ID”, “character2ID”, “movieID”, “utteranceIDs”]
Load lines and process conversations
print(“\nProcessing corpus…”)
lines = loadLines(os.path.join(corpus, “movie_lines.txt”), MOVIE_LINES_FIELDS)
print(“\nLoading conversations…”)
conversations = loadConversations(os.path.join(corpus, “movie_conversations.txt”),
lines, MOVIE_CONVERSATIONS_FIELDS)
Write new csv file
print(“\nWriting newly formatted file…”)
with open(datafile, ‘w’, encoding=‘utf-8’) as outputfile:
writer = csv.writer(outputfile, delimiter=delimiter)
for pair in extractSentencePairs(conversations):
writer.writerow(pair)
Print a sample of lines
print(“\nSample lines from file:”)
printLines(datafile)
Default word tokens
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
class Voc:
def init(self, name):
self.name = name
self.trimmed = False
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: “PAD”, SOS_token: “SOS”, EOS_token: “EOS”}
self.num_words = 3 # Count SOS, EOS, PAD
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
self.word2count[word] += 1
# Remove words below a certain count threshold
def trim(self, min_count):
if self.trimmed:
return
self.trimmed = True
keep_words = []
for k, v in self.word2count.items():
if v >= min_count:
keep_words.append(k)
print('keep_words {} / {} = {:.4f}'.format(
len(keep_words), len(self.word2index), len(keep_words) / len(self.word2index)
))
# Reinitialize dictionaries
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3 # Count default tokens
for word in keep_words:
self.addWord(word)
MAX_LENGTH = 10 # Maximum sentence length to consider
Turn a Unicode string to plain ASCII, thanks to
http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ‘’.join(
c for c in unicodedata.normalize(‘NFD’, s)
if unicodedata.category(c) != ‘Mn’
)
Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])“, r” \1", s)
s = re.sub(r"[^a-zA-Z.!?]+“, r” “, s)
s = re.sub(r”\s+“, r” ", s).strip()
return s
Read query/response pairs and return a voc object
def readVocs(datafile, corpus_name):
print(“Reading lines…”)
# Read the file and split into lines
lines = open(datafile, encoding=‘utf-8’).
read().strip().split(‘\n’)
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split(‘\t’)] for l in lines]
voc = Voc(corpus_name)
return voc, pairs
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(’ ‘)) < MAX_LENGTH and len(p[1].split(’ ')) < MAX_LENGTH
Filter pairs using filterPair condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
Using the functions defined above, return a populated voc object and pairs list
def loadPrepareData(corpus, corpus_name, datafile, save_dir):
print(“Start preparing training data …”)
voc, pairs = readVocs(datafile, corpus_name)
print(“Read {!s} sentence pairs”.format(len(pairs)))
pairs = filterPairs(pairs)
print(“Trimmed to {!s} sentence pairs”.format(len(pairs)))
print(“Counting words…”)
for pair in pairs:
voc.addSentence(pair[0])
voc.addSentence(pair[1])
print(“Counted words:”, voc.num_words)
return voc, pairs
save_dir = os.path.join(“data”, “save”)
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
Print some pairs to validate
print(“\npairs:”)
for pair in pairs[:10]:
print(pair)
File “”, line 1, in
runfile(‘C:/Users/lab723/Desktop/glove1005/untitled0.py’, wdir=‘C:/Users/lab723/Desktop/glove1005’)
File “C:\Users\lab723\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 705, in runfile
execfile(filename, namespace)
File “C:\Users\lab723\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 102, in execfile
exec(compile(f.read(), filename, ‘exec’), namespace)
File “C:/Users/lab723/Desktop/glove1005/untitled0.py”, line 219, in
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
File “C:/Users/lab723/Desktop/glove1005/untitled0.py”, line 209, in loadPrepareData
pairs = filterPairs(pairs)
File “C:/Users/lab723/Desktop/glove1005/untitled0.py”, line 202, in filterPairs
return [pair for pair in pairs if filterPair(pair)]
File “C:/Users/lab723/Desktop/glove1005/untitled0.py”, line 202, in
return [pair for pair in pairs if filterPair(pair)]
File “C:/Users/lab723/Desktop/glove1005/untitled0.py”, line 198, in filterPair
return len(p[0].split(’ ‘)) < MAX_LENGTH and len(p[1].split(’ ')) < MAX_LENGTH
IndexError: list index out of range