I’m currently implementing a recurrent PPO policy and as of now it works for gym-minigrid-hallway and CartPole (masked velocity). However, I’ve got quiet some open questions left that leave me in doubts about my implementation.
In comparison to a none-recurrent PPO implementation, I just added the hidden states of a GRU layer to the agents’ experience tuples. Concerning the sampling of mini batches, I make sure that sequences are maintained for each agent. That are all the changes I’ve made.
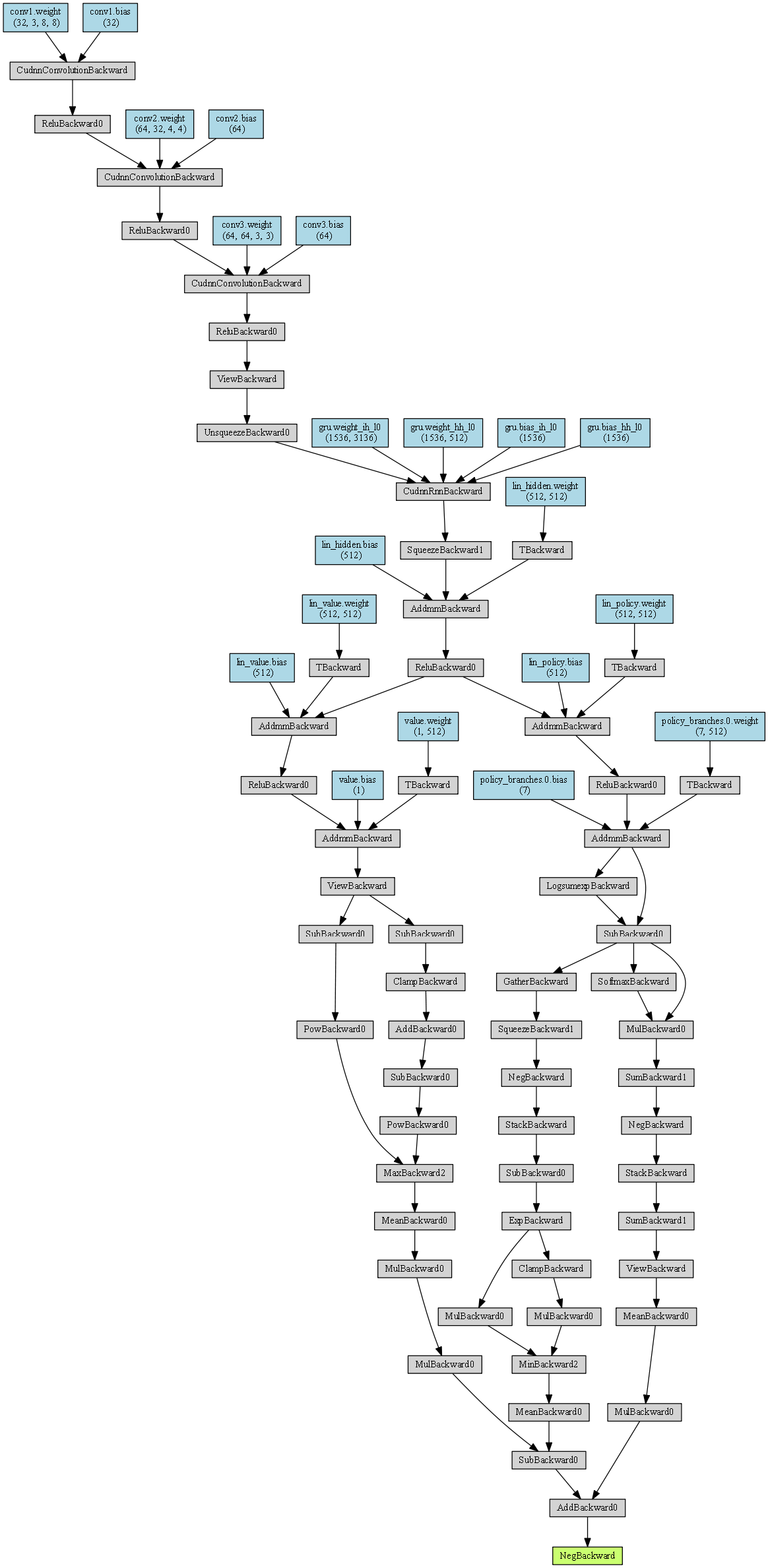
One odd thing is that one PPO cycle/update does not take longer to compute while using the recurrent policy. I expected it to be notably more expensive. This raises the question to me whether the sequence of hidden states are back-propagated correctly. How could I check/verify that the gradients flow into the whole sequence of experience tuples, while not flowing into a new episode?
I’m struggling now to identify the information about how many hidden_states are back-propagated.
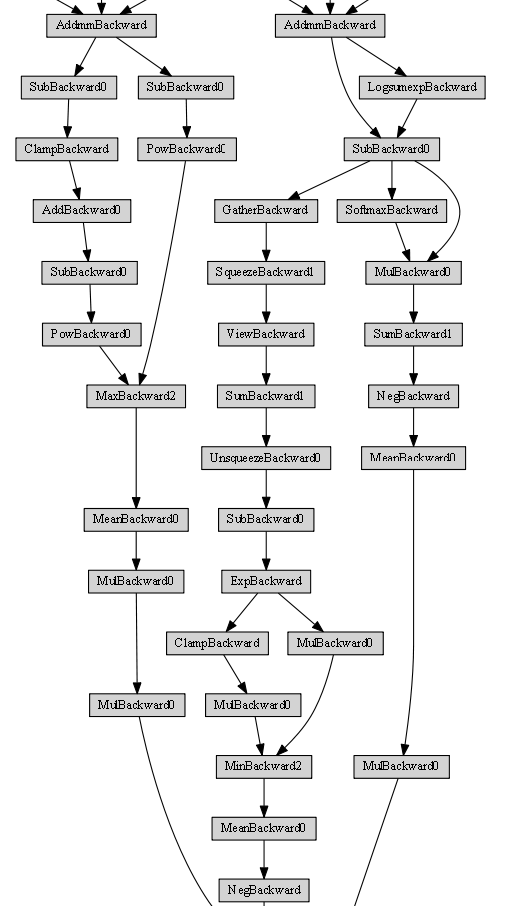
Should multiple gru nodes be apparent if sequences of hidden states were back-propagated?
I just recalled that hidden states are also stored as the current_state and next_state entries, and they are detached, so a single GRU layer is possible, since in this scenario, gradients will not flow through those detached hidden states. It really depends on your model implementation.
I also noticed that you have serveral different modules in the bottom PPO part, compared to that repo, may be you should also check those modules? It is also possible that you may have wrongly implemented PPO, there are many possibilities.
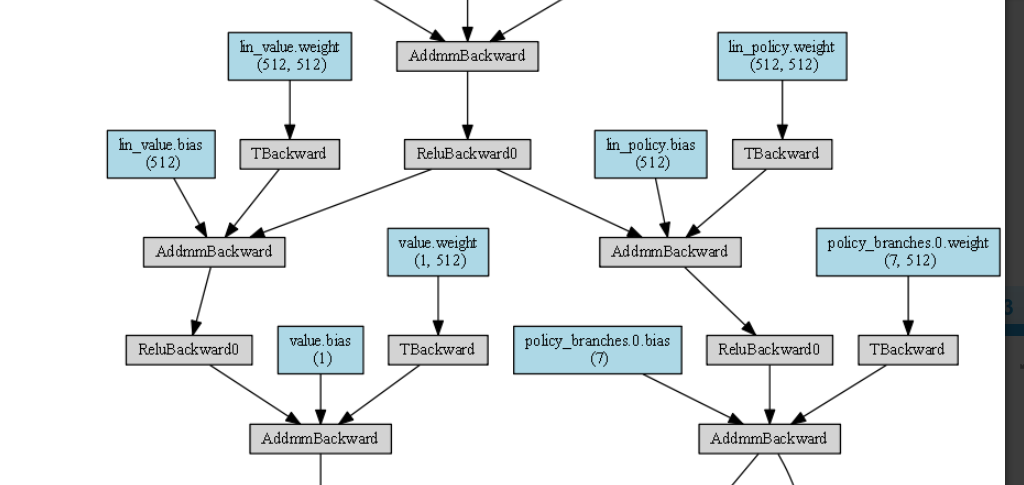
Yes, but it depends on your model. if in each time step, you are just feeding the last hidden state h(t-1), the observed state x(t) into your GRU layer (this is the basic GRU / LSTM/ RNN model), then there should be only one GRU layer in your flow graph.
And if you are feeding more history states (such as 4), then you will see more GRU layers.
I think you shouldn’t be storing the hidden states of the GRU in the experience buffer. Or if you do, you shouldn’t be feeding those as constants since autograd needs to know that gradients have to backpropagate through time. Every time you do an update you should feed all the observations in the sequence, and let the network recompute its hidden states.
There is also the question of what should be the initial hidden state of that sequence. In DRQN people normally use a vector of zeros, since the hidden states of the GRU can be very different when the experience was collected than when the experience is actually used for updating the network. However, for PPO you can actually use the hidden state that was computed while interacting with the environment.
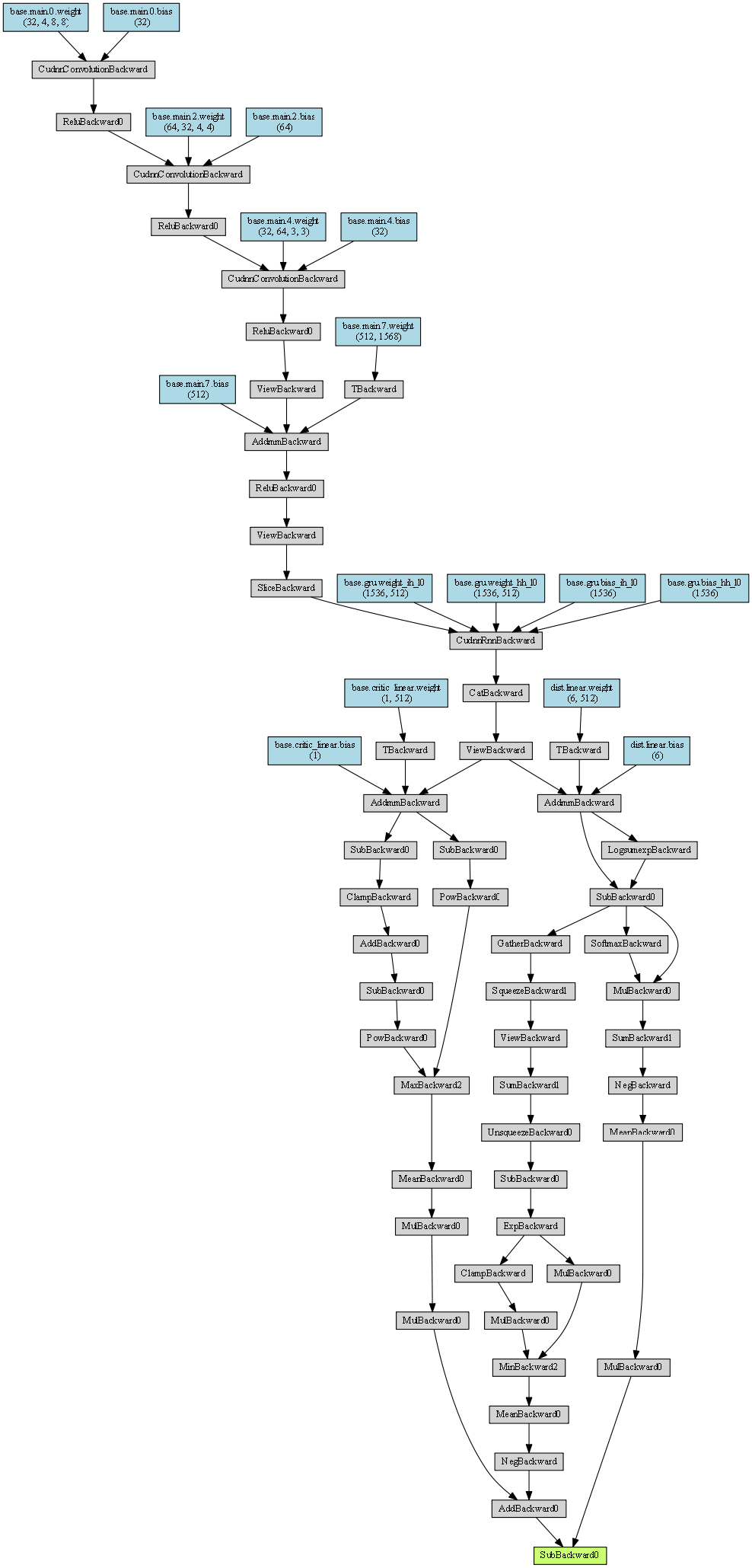
The sequence length is defined as 12 and it looks like that some structure of this graph is repeated 12 times. But this behavior is not apparent for this repo: ikostrikov/pytorch-a2c-ppo-acktr-gail (see one of the graphs above). In that repo, the hidden states are recomputed during the mini batch updates.