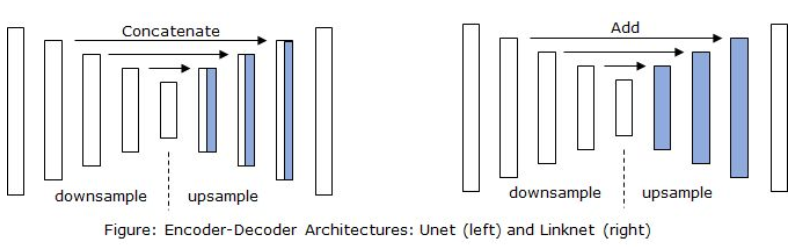
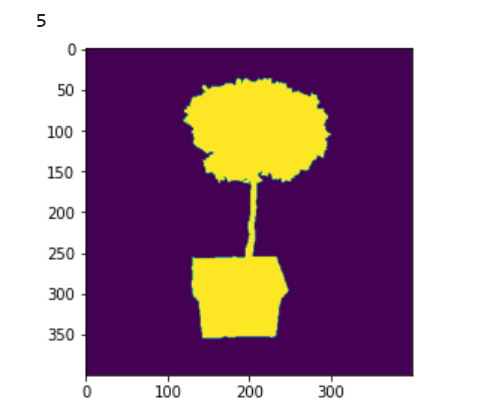
I slightly modified the Unet and now I experience this
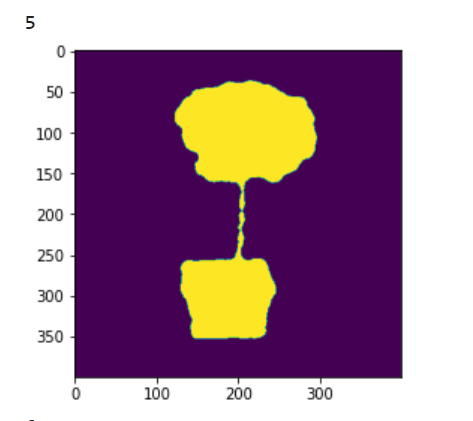
for the GT of
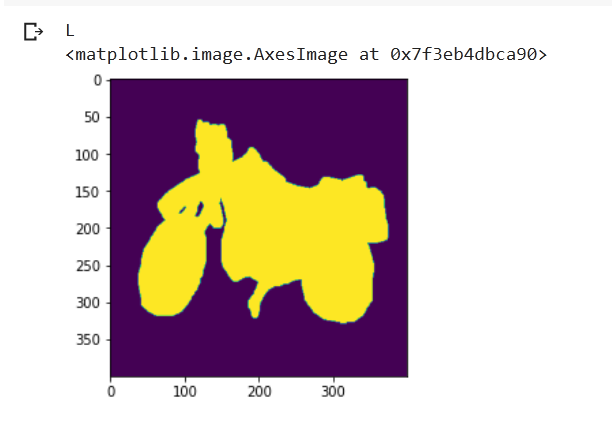
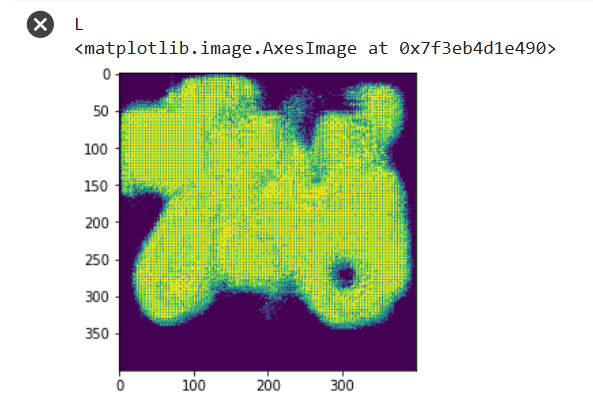
I assume this is due to ConvTranspose2D. How to overcome this?
class UpConv(nn.Module):
def __init__(self, in_channels, in_channels_skip, out_channels,
kernel_size, padding, stride):
super(UpConv, self).__init__()
self.act = nn.ReLU()
self.conv_trans1 = nn.ConvTranspose2d(in_channels, in_channels, kernel_size=2, padding=0, stride=2)
self.bn1 = nn.BatchNorm2d(in_channels, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.bn2 = nn.BatchNorm2d(out_channels, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
self.conv_block = BaseConv(
in_channels=in_channels + in_channels_skip,
out_channels=out_channels,
kernel_size=kernel_size,
padding=padding,
stride=stride)
def forward(self, x, x_skip):
x = self.act(self.bn1(self.conv_trans1(x)))
x = torch.cat ((x, x_skip[:, :, :x.shape[2], :x.shape[3]]), dim = 1)
x = self.act(self.bn2(self.conv_block(x)))
return x
I am using always 400x400 images to train so the slicing is really not that needed x and x_skip do match for the cat always.