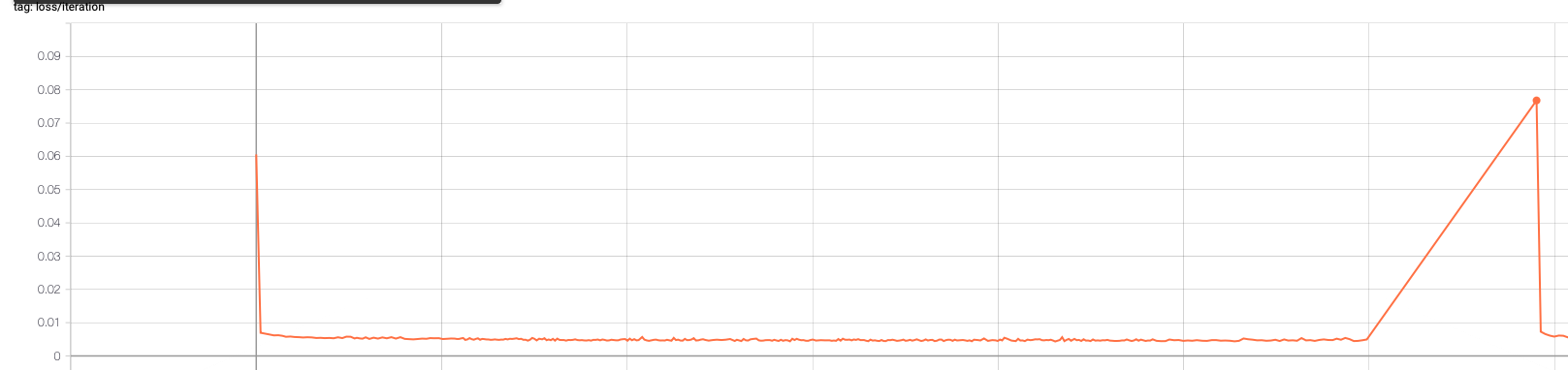
Hi all! Recently, I started implementing checkpoint saves on my code, as it has become difficult running everything in one go. I save everything as prescribed on the PyTorch tutorials, however when I resume training, the network behaves as if the checkpoint hasn’t been loaded properly. You can see this behaviour in the figure below. I’ll also include relevant extracts from my code, in case anybody can spot if I am doing something silly. Thank you!
class Solver():
def __init__(self ... ):
self.model = model
self.optimizer = optimizer(model.parameters(), **optimizer_arguments)
....
self.model_name = model_name
....
self.learning_rate_scheduler = lr_scheduler.StepLR(self.optimizer,
step_size=learning_rate_scheduler_step_size,
gamma=learning_rate_scheduler_gamma)
self.start_epoch = 1
self.start_iteration = 1
....
if use_last_checkpoint:
self.load_checkpoint()
def train(self, train_loader, validation_loader):
model, optimizer, learning_rate_scheduler = self.model, self.optimizer, self.learning_rate_scheduler
if torch.cuda.is_available():
torch.cuda.empty_cache() # clear memory
model.cuda(self.device) # Moving the model to GPU
iteration = self.start_iteration
for epoch in range(self.start_epoch, self.number_epochs+1):
......
if phase == 'train':
model.train()
else:
model.eval()
.....
with torch.no_grad():
....
if phase == 'validation':
early_stop, save_checkpoint = self.EarlyStopping(
np.mean(losses))
self.early_stop = early_stop
if save_checkpoint == True:
validation_loss = np.mean(losses)
checkpoint_name = os.path.join(
self.experiment_directory_path, self.checkpoint_directory, 'checkpoint_epoch_' + str(epoch) + '.' + checkpoint_extension)
self.save_checkpoint(state={'epoch': epoch + 1,
'start_iteration': iteration + 1,
'arch': self.model_name,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': learning_rate_scheduler.state_dict()
},
filename=checkpoint_name
)
......
if phase == 'train':
learning_rate_scheduler.step()
......
def save_checkpoint(self, state, filename):
torch.save(state, filename)
def load_checkpoint(self, epoch=None):
....
checkpoint_file_path = os.path.join(.....)
self._checkpoint_reader(checkpoint_file_path)
def _checkpoint_reader(self, checkpoint_file_path):
....
checkpoint = torch.load(checkpoint_file_path)
self.start_epoch = checkpoint['epoch']
self.start_iteration = checkpoint['start_iteration']
self.model.load_state_dict = checkpoint['state_dict']
self.optimizer.load_state_dict = checkpoint['optimizer']
for state in self.optimizer.state.values():
for key, value in state.items():
if torch.is_tensor(value):
state[key] = value.to(self.device)
self.learning_rate_scheduler.load_state_dict = checkpoint['scheduler']
