Hi guys,
I’m trying to train a model based on HuggingFace (Pytorch backend) and I have a problem and I was hoping that I might get some help here (there was no answer on HF unfortunately). After a certain number of steps (~8000) my checkpoints only contain a rng_state.pth file:
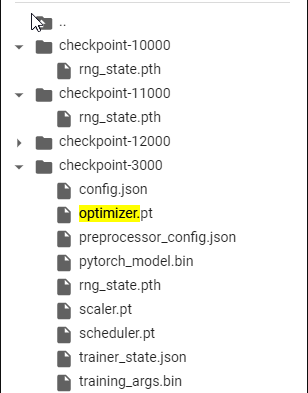
** Marker unrelated **
Why could this be the case? I sync my checkpoints automatically to resum training if Colab Crashes. Unfortually out of 22 Checkpoints (1-23k) only the first 6 (1k - 7k) are valid (all required data included).
TrainingArguments(
output_dir=/share/datasets/output_run,
overwrite_output_dir=True,
do_train=True,
do_eval=True,
do_predict=False,
evaluation_strategy=IntervalStrategy.STEPS,
prediction_loss_only=False,
per_device_train_batch_size=20,
per_device_eval_batch_size=16,
gradient_accumulation_steps=1,
eval_accumulation_steps=None,
learning_rate=0.0001,
weight_decay=0.0,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
max_grad_norm=1.0,
num_train_epochs=20.0,
max_steps=-1,
lr_scheduler_type=SchedulerType.LINEAR,
warmup_ratio=0.0,
warmup_steps=0,
logging_dir=runs/May12_05-06-46_a600ce861ff7,
logging_strategy=IntervalStrategy.STEPS,
logging_first_step=False,
logging_steps=1000,
save_strategy=IntervalStrategy.STEPS,
save_steps=1000,
save_total_limit=3,
no_cuda=False,
seed=42,
fp16=True,
fp16_opt_level=O1,
fp16_backend=auto,
fp16_full_eval=False,
local_rank=-1,
tpu_num_cores=None,
tpu_metrics_debug=False,
debug=[],
dataloader_drop_last=False,
eval_steps=1000,
dataloader_num_workers=2,
past_index=-1,
run_name=cv_sm_1,
disable_tqdm=False,
remove_unused_columns=True,
label_names=None,
load_best_model_at_end=True,
metric_for_best_model=loss,
greater_is_better=False,
ignore_data_skip=False,
sharded_ddp=[],
deepspeed=None,
label_smoothing_factor=0.0,
adafactor=False,
group_by_length=True,
length_column_name=length,
report_to=['wandb'],
ddp_find_unused_parameters=None,
dataloader_pin_memory=True,
skip_memory_metrics=False,
use_legacy_prediction_loop=False,
push_to_hub=False,
resume_from_checkpoint=None,
_n_gpu=1,
mp_parameters=
)
Ty in advcane
Edit://
According to the Trainer Output the File are created:
Saving model checkpoint to /share/datasets/output_run/checkpoint-24000
Configuration saved in /share/datasets/output_run/checkpoint-24000/config.json
Model weights saved in /share/datasets/output_run/checkpoint-24000/pytorch_model.bin
Configuration saved in /share/datasets/output_run/checkpoint-24000/preprocessor_config.json
But i could not validate that using File Explorer, ls /share/datasets/output_run/checkpoint-24000/.
I also tried to search on the entire Drive !find / -name optimizer.pt but i could only find pytorch_model.bin etc on the “valid” Checkpoints i mentioned above (1-7k), and there fore only for Checkpoints < 7000.