torch.compile is the latest method to speed up your PyTorch code! torch.compile makes PyTorch code run faster by JIT-compiling PyTorch code into optimized kernels, all while requiring minimal code changes.
Does that mean if I use torch.compile on models/functions, it gives similar optimization of kernel fusion with triton?
What’s the difference between torch.compile and triton? Is either one sufficient for optimization, or can they be used orthogonally at the same time?
I’m new to all this kind of optimizations and super curious, any suggestions or references would be greatly appreciated! Thanks!
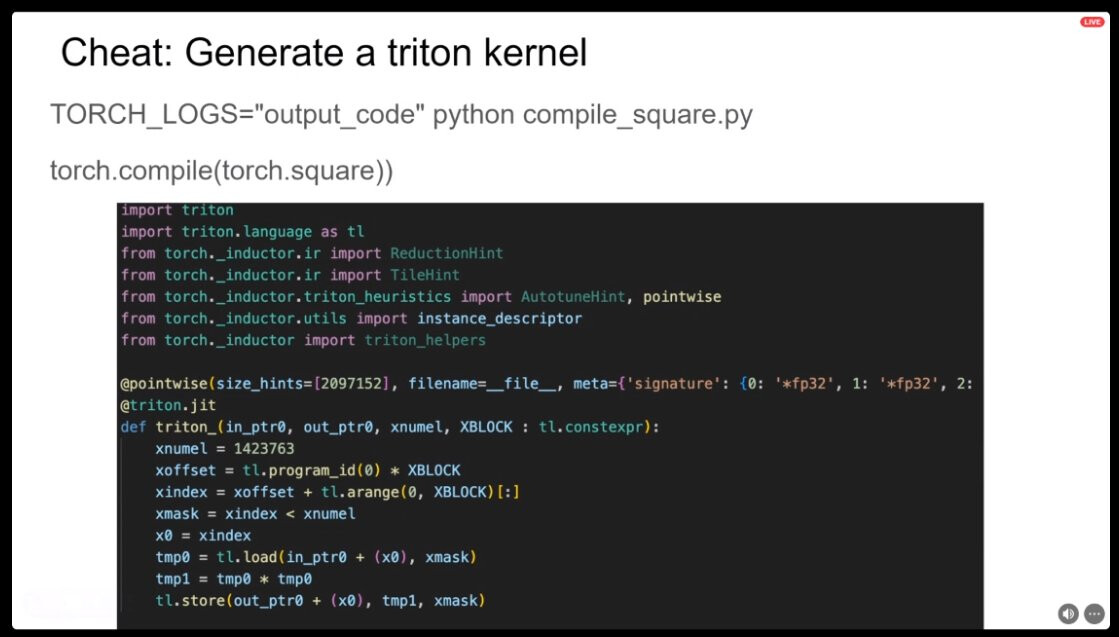
On GPUs torch.compile() will apply various compiler optimizations with the most important ones being cuda graphs and fusions. Fusions specifically are done by code generating triton kernels so torch.compile() is actually a great starting point for writing triton kernels and you can always take that and try to write something faster yourself.
@marksaroufim Thank you! Would it be possible to share the talk?
torch.compile() is actually a great starting point for writing triton kernels and you can always take that and try to write something faster yourself.
I don’t quite follow here: does that mean that torch.compile() can generate human-readable triton kernel files, and people can make manual tweaks from there and put them back to the model definition? My usage of torch.compile is simply wrapping a model with it during training.
@marksaroufim May I ask to what extent torch.compile optimizes the computation for users? Given how powerful torch.compile is, should we always use it first before writing triton/CUDA kernels for extra efficiency?
I found many tutorials (triton, torch.compile, CUDA, etc) about making the model more efficient but just not sure if they are interchangeable.
The main optimizations torch.compile will perform are
Fusions
CUDA graphs
Template matching for SDPA (i.e: flash attention)
It’s also an active project so I’m sure there’s more in flux. Can’t say what you should always do but personally yes I always reach for torch.compile first before attempting to write a custom kernel
hi @marksaroufim. Why can’t torch.compile figure out the flash attention optimization part on it’s own? we have to use torch’s custom attention to get the flash attention speedup…
Granted if a compiler knows about the online softmax trick then you could plausibly do more code generation for things like Flash Attention. There are cool prototypes for this by startups like luminal but last I checked their benchmarks were for FA-1 because each new versioned release adds more tricks