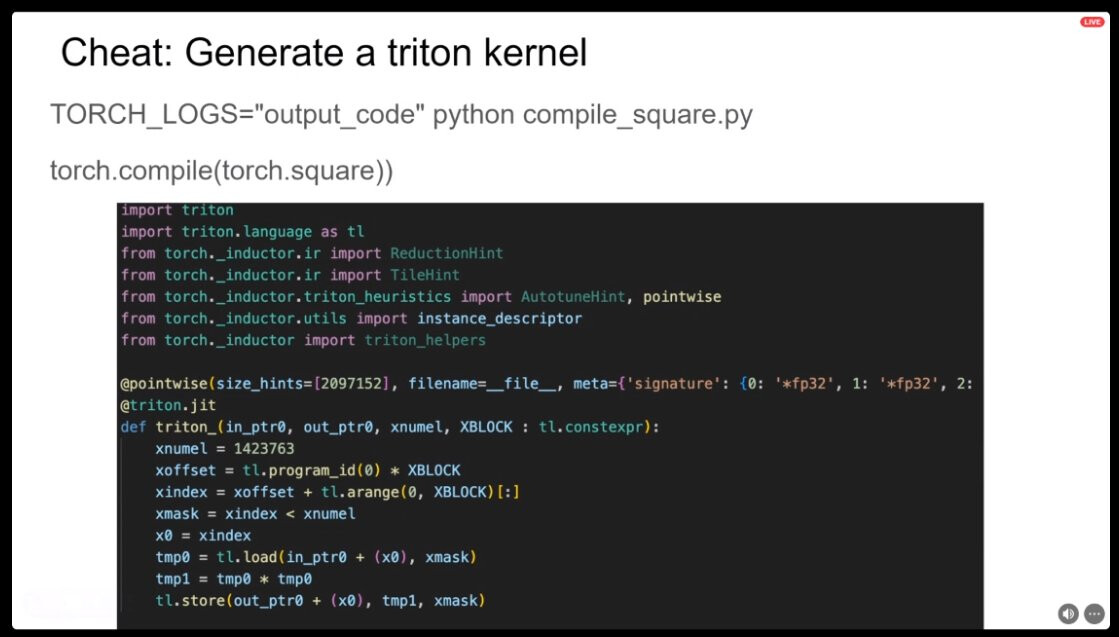
On GPUs torch.compile() will apply various compiler optimizations with the most important ones being cuda graphs and fusions. Fusions specifically are done by code generating triton kernels so torch.compile() is actually a great starting point for writing triton kernels and you can always take that and try to write something faster yourself.
From a recent talk I gave