I have a question about the LSTM model. If initialize the hidden state vector during the forward method and proceed to train the model with training data, then if I were to evaluate model performance with some test data, would the hidden state vector be re-initialized as zeros even if I were to call with torch.no_grad() ?
A simple example that I have is the one from pytorch examples time series prediction with a slight modification as follows:
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.optim as optim
import torch.utils.data
import torch.nn as nn
# helper function to convert numpy array to tensor
def to_tensor(numpy_array, dtype = 'float'):
if dtype == 'long':
return torch.from_numpy(numpy_array).long()
else:
return torch.from_numpy(numpy_array).float()
# helper function to convert tensor to variable
def to_variable(tensor):
if torch.cuda.is_available():
tensor = tensor.cuda()
return torch.autograd.Variable(tensor)
class SequenceLSTM(nn.Module):
def __init__(self):
super(SequenceLSTM, self).__init__()
self.lstm1 = nn.LSTM(1, 51, 2)
self.linear = nn.Linear(51,1)
def forward(self, input):
self.h = torch.zeros(2, 1, 51).cuda()
self.c = torch.zeros(2, 1, 51).cuda()
output, h = self.lstm1(input.view(input.size(1),input.size(0),1), (self.h, self.c))
output = self.linear(output)
return output.squeeze(2)
# Generate training data
np.random.seed(2)
T = 20
L = 1000
N = 100
x = np.empty((N, L), 'int64')
x[:] = np.array(range(L)) + np.random.randint(-4 * T, 4 * T, N).reshape(N, 1)
data = np.sin(x / 1.0 / T).astype('float64')
# split training set
input = torch.from_numpy(data[3:, :500]).float()
target = torch.from_numpy(data[3:, 1:501]).float()
# split test set
test_input = torch.from_numpy(data[:3, 500:700]).float()
test_target = torch.from_numpy(data[:3, 501:701]).float()
# initialize model
criterion = nn.MSELoss().cuda()
seq = SequenceLSTM()
seq.cuda()
dataset = torch.utils.data.TensorDataset(input, target)
test_dataset = torch.utils.data.TensorDataset(test_input, test_target)
data_loader = torch.utils.data.DataLoader(dataset, batch_size = 1)
test_data_loader = torch.utils.data.DataLoader(test_dataset, batch_size = 1)
optimizer = optim.Adam(seq.parameters(), lr=1e-3)
losses = []
timer = []
for epoch in range(1):
for i, (train, test) in enumerate(dataset):
train = train.view(-1, train.size(0)) # tensor of size (1, 999)
optimizer.zero_grad()
train, test = to_variable(train), to_variable(test)
output = seq(train)
loss = criterion(output, test.view(test.size(0), 1))
loss.backward()
losses.append(loss.item())
optimizer.step()
print('Loss is : ', loss.item())
y_pred_train = []
ypred_test = []
with torch.no_grad():
for test_inp, test_target in test_data_loader:
future = 1000
test_target = test_target.view(test_target.size(1), 1)
test_inp = test_inp.view(-1, test_inp.size(1))
pred = seq(test_inp.cuda())
loss = criterion(pred, test_target.cuda())
print('test loss:', loss.item())
y = pred.cpu().data.numpy()
ypred_test.append(y)
# sanity check to see predictions against actual
ypred_test = np.hstack(ypred_test)
y_df = pd.DataFrame(ypred_test.T[0, :], columns = ['predicted'])
y_df['actual'] = data[0, 501 : 701]
y_df.plot()
plt.show()
So my question is about the details of what happens during the with torch.no_grad():
- when I pass in the test data, does it uses the hidden state parameters learned from the training period or is my model doing something redundant ?
I understand that the hidden state needs to be initialized as zeros in the very beginning but am struggling to wrap my head around this because the prediction output, based on the test input looks as follows, and it seems like that it is getting quite good results so I am slightly confused.
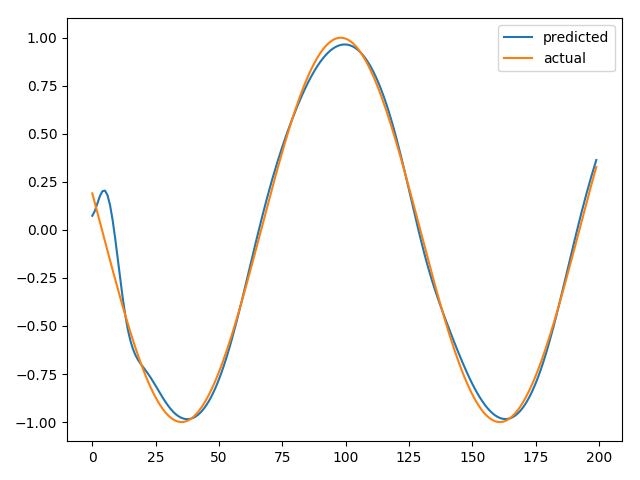
I am a bit new to sequence models with pytorch so I would greatly appreciate any clarifications.