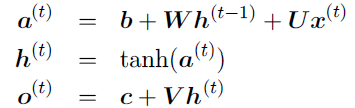Hey,
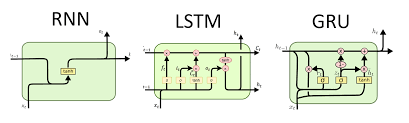
I am trying to design an RNN-based model that processes time series data. In principle, I don’t understand the exact usages of output and h_n.
In my understanding, output is for instance a matrix (batch_size,L,Hout), where L = 0,…,t (sort of) and Hout is the number of output features (i.e. number of entries in the hidden state vector. Therefore, output is like a matrix containing [h_0|h_1|…|h_L]. Thus, if we wanted to have just the last / most recent hidden state, we would simply slice the last column h_L of that matrix?
And then there is h_n, which, as I understand, is exactly this last column of the matrix? Is this returned for convenience? Or do I misunderstand the whole thing?
Furthermore, if we wanted to learn the output of the rnn cell with a different dimension than the hidden state has, we would put for instance a fully connected layer with dimension (Hout,O) “on top” of the last state of the rnn, where O is the intended size of the output? Then, if we wanted to return an entire sequence, we would apply the learned hidden-to-output function with weight matrix dimension (Hout,O) to as many past hidden states as the desired prediction sequence length?
Hope these formulations are clear, I am still just finding my way around the theory.
Best, JZ