Hi,
Let me explain it step by step.
-
Here is kaiming_uniform_.
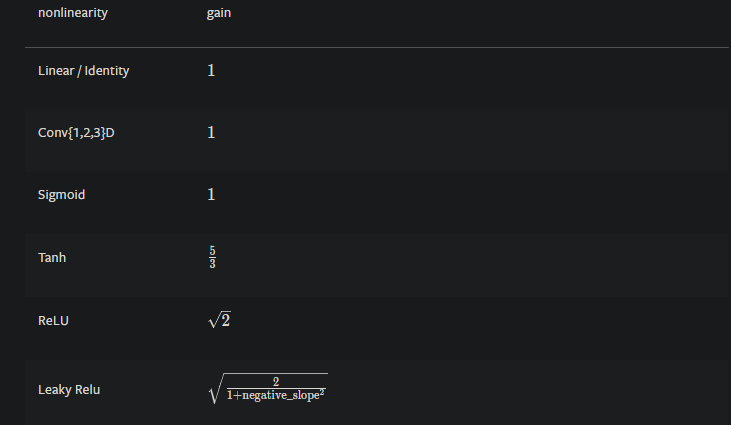
Wherenegative_slope=sqrt(5)so thegain=sqrt(2/6)=1/sqrt(3)for kaiming.
If we replace this inboundformula, we getbound = [1/sqrt(3) ] * [sqrt(3/ fan_in)]which with a little simplification, it will bebound = 1/sqrt(fan_in)which can be represented bybound^2 = 1 / fan_in. -
In linear implementation code you referenced:

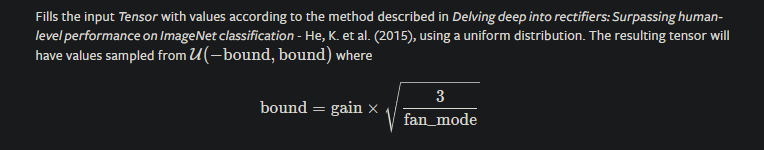

So what we have here is that k= 1/in_feautres which in case of kaming it can be represented k=1/fan_in. Also, we want a boundary of [-sqrt(k), sqrt(k)] where k = bound^2= 1 / fan_in from step 1.
For simplcity, just replace sqrt(5) in gain formula then optain bound in kaiming_uniform_ and replace the bound as k in linear.
Edit: Add some related posts
- Kaiming init of conv and linear layers, why gain = sqrt(5) · Issue #15314 · pytorch/pytorch · GitHub
- Why the default negative_slope for kaiming_uniform initialization of Convolution and Linear layers is √5?
Bests