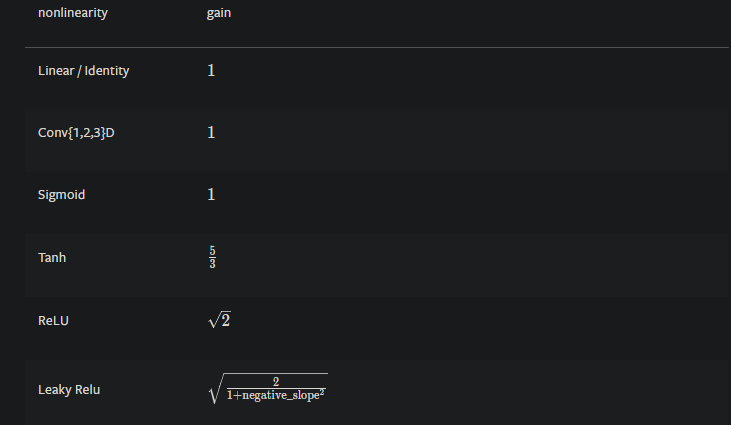
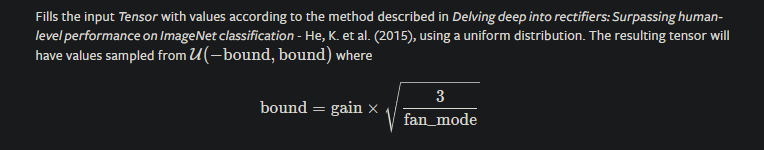According to the documentation for torch.nn, the default initialization uses a uniform distribution bounded by 1/sqrt(in_features), but this code appears to show the default initialization as Kaiming uniform. Am I correct in thinking these are not the same thing? And if so, perhaps the documentation can be updated?
Does anyone know the motivation for this choice of default? In particular, the code appears to define a negative slope for the subsequent nonlinearity of sqrt(5), whereas the default negative slope for a leaky relu in pytorch is 0.01. Also, does anyone know how this negative slope is actually incorporated into the initialization?