Hi everyone,
I am new to Pytorch, and in the last couple of days I have been struggling with the class Dataset that lets you build your custom dataset.
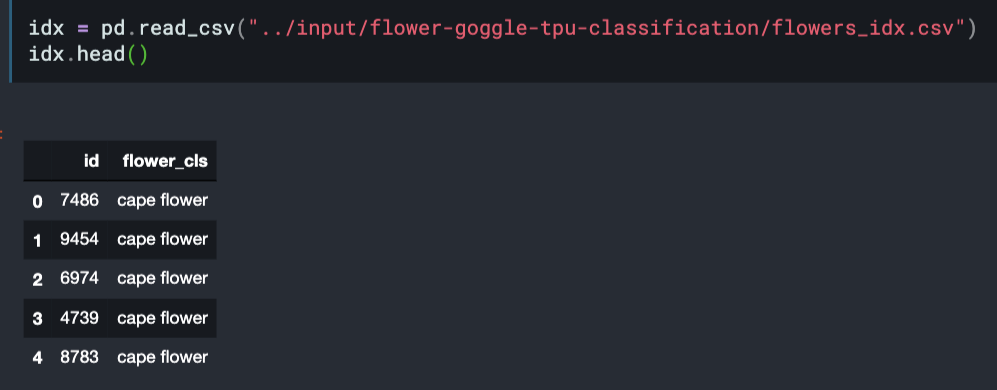
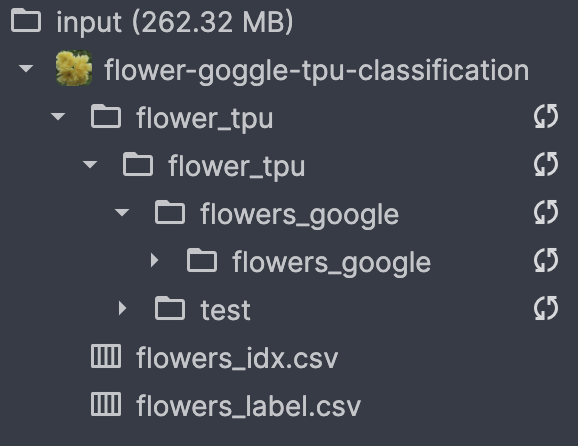
I am working with this dataset (https://www.kaggle.com/ianmoone0617/flower-goggle-tpu-classification/kernels) , the problem is that it has the images and their labels in separate folders, and I can’t figure out how to concatenate them.
I found this notebook (it’s not mine) where there is the code that performs the class Dataset, however I simply cannot understand it. The part I do not understand is the one where he iterates all files, could you guys be so kind to help me understand it? thank you so much in advance! 
class MyDataset(Dataset):
def __init__(self, image_dir, label_dir, transform=None):
_images, _labels = [], []
# total amount of dataset
_number = 0
# Reading the categorical file
label_df = pd.read_csv(label_dir)
# Iterate all files including .jpg images
for subdir, dirs, files in tqdm(os.walk(image_dir)):
for filename in files:
if len(subdir.split(os.sep)) >5:
# 注意到 這裡如果不能讀檔一定是這裡發生問題,路徑要檢查一下
corr_label = label_df[label_df['dirpath']==os.sep.join(subdir.split(os.sep)[5:])]['label'].values
if corr_label.size!= 0 and filename.endswith(('jpg')):
_images.append(subdir + os.sep + filename)
_labels.append(corr_label)
_number+=1
# Randomly arrange data pairs
mapIndexPosition = list(zip(_images, _labels))
random.shuffle(mapIndexPosition)
_images, _labels = zip(*mapIndexPosition)
self._image = iter(_images)
self._labels = iter(_labels)
self._number = _number
self._category = label_df['label'].nunique()
self.transform = transform
def __len__(self):
return self._number
def __getitem__(self, index):
img = next(self._image)
lab = next(self._labels)
img = self._loadimage(img)
if self.transform:
img = self.transform(img)
return img, lab
def _categorical(self, label):
return np.arange(self._category) == label[:,None]
def _loadimage(self, file):
return Image.open(file).convert('RGB')
def get_categorical_nums(self):
return self._category