Hello,
I am very new to pytorch and DNNs in general.
I’ve created a classifier on top of a pretrained densenet161, to classify images of flowers, into the groups: daisy(0), dandelion(1), rose(2), sunflower(3) and tulip(4).
The training-process works fine and in order to test the model I went on implementing the example from chaper 5 of the tutorial from the PyTorch site.
All this seems to work, the classifier predicts a defined set of images with an acceptable performance but the next thing I wanted to do, was to test it with a single image.
The first step was to simply set the batch-size to one but at this point the output of my network is wrong.
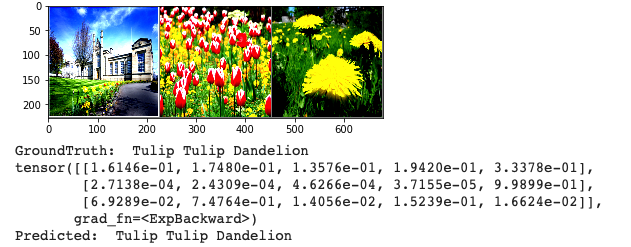
This is the output tensor of the working example, the index of these classes is mapped like shown above.
After this worked, i tried to load a single image like this:
test_transforms = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
def make_image(image):
image_tensor = test_transforms(image)
image_tensor.unsqueeze_(0)
return image_tensor
img = make_image(Image.open("path-to-a-sunflower"))
output = torch.exp(model.forward(img)) # exp because of LogSoftMax as output layer
print(output)
val, pos = out.topk(1,dim=1)
Via the topk I wanted to get the position of the highest value in order to display the class.
The output of the model was:
tensor([[0.1126, 0.2525, 0.1020, 0.0674, 0.4655]], grad_fn=)
which means that it has classified the picture as a tulip.
The strange thing is, that if I try the same images within a dataloader with identical transformation, the results are just right.
I have no idea where to start with this problem, so I wonder if there is a reason for this behavior and, in the best case a solution.
To provide more information I will post some of the Code here, I hope this helps.
Classifier, Criterion and Optimizer:
model.classifier = nn.Sequential(nn.Linear(model.classifier.in_features, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 265),
nn.ReLU(),
nn.Linear(265,5),
nn.LogSoftmax(dim=1))
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.classifier.parameters(), lr=0.003)
The Epoch Loop
for epoch in range(epochs):
for inputs, labels in tqdm_notebook(trainloader,desc="Training batches"):
steps += 1
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
logps = model.forward(inputs)
loss = criterion(logps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for inputs, labels in tqdm_notebook(testloader,desc="Testing batches",leave = False):
inputs, labels = inputs.to(device), labels.to(device)
logps = model.forward(inputs)
batch_loss = criterion(logps, labels)
test_loss += batch_loss.item()
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor)).item()
# plotting
train_losses.append(running_loss / len(trainloader))
test_losses.append(test_loss / len(testloader))
print(f"Epoch {epoch + 1}/{epochs}.. "
f"Train loss: {running_loss / print_every:.3f}.. "
f"Test loss: {test_loss / len(testloader):.3f}.. "
f"Test accuracy: {accuracy / len(testloader):.3f}")
running_loss = 0
model.train()
I hope these informations could describe my problem and I appreciate any idea concerning this topic. Thank you very much in advance.