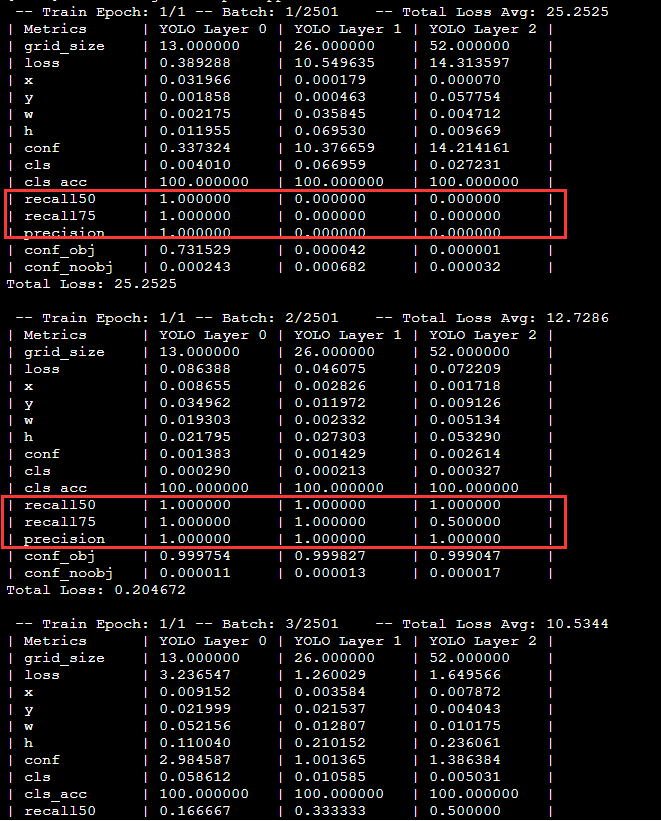
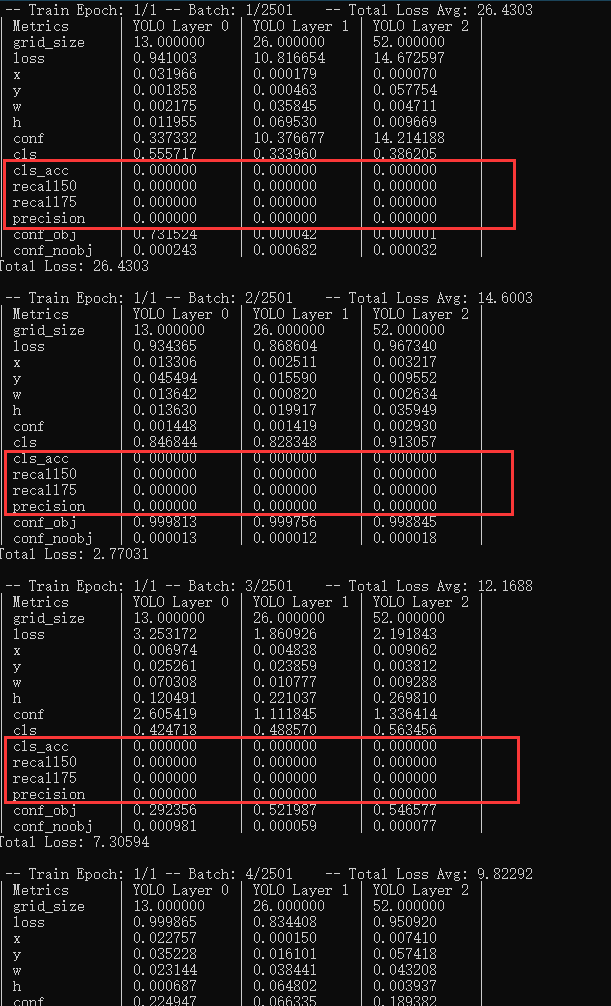
I implemented YOLOv3 using libtorch and trained with Telsa V100 on the server several times until the recall level was high enough. However, when I turned the model into a CPU version and saved it, I used the same code on my laptop and found that the recall was extremely low. Therefore, I designed a comparison experiment. Using the model, code and training set exactly the same as those in the laptop on the server, the running result display was quite different from the result on my laptop in recall. As is shown in
running windows10 with also CPU mode, libtorch 1.5.0.
You can see the apparent difference in metrics.
This is a completely incomprehensible result, and I’ve managed to control the variables as much as possible, except for the difference between the two operating systems and the hardware systems.I don’t know if this is a normal phenomenon, but if there is such a huge difference between different systems, how do you transplant pre-training weights?
There might be several different issues, so let’s split them up.
The pretrained model should give you approx. the same outputs up to the limited floating point precision. Especially while using different hardware, you might not be able to overcome the absolute errors introduces by the floating point precision. If you load the state_dict properly, set model.eval(), and still get largely different results, we would need to see the code to debug further.
Training on different platform might also yield slightly different results due to the aforementioned reasons. However, it would be interesting to see how reliable the difference is. I.e. out of e.g. 10 runs on each platform with different seeds, how often does one model converge while the other diverges?
I can certainly understand the floating point differences between platforms, but it seems that I have encountered more than I expected. I thought about it for a while, but I still didn’t know how to solve the problem. For example, I would eventually deploy to a laptop, so would I eventually have to train on a laptop? In my experience, this doesn’t make much sense.
On the other hand, you mentioned the need to see the code to debug further. so how exactly to do that?
No, as mentioned above, the pretrained model should give you the same outputs up the the floating point precision.
You could write an evluation script, which loads the model, uses a constant tensor, applies the forward pass, and prints the output.
Post this code here by wrapping it into three backticks ``` and also post the outputs from the Linux server and your laptop.
Assuming you are running this code snippet on both machines, I would recommend to check the intermediate tensors such as the output as well as the output activations using hooks.
If I’m not mistaken, forward hooks are not available in libtorch yet, so you could use the Python frontend.