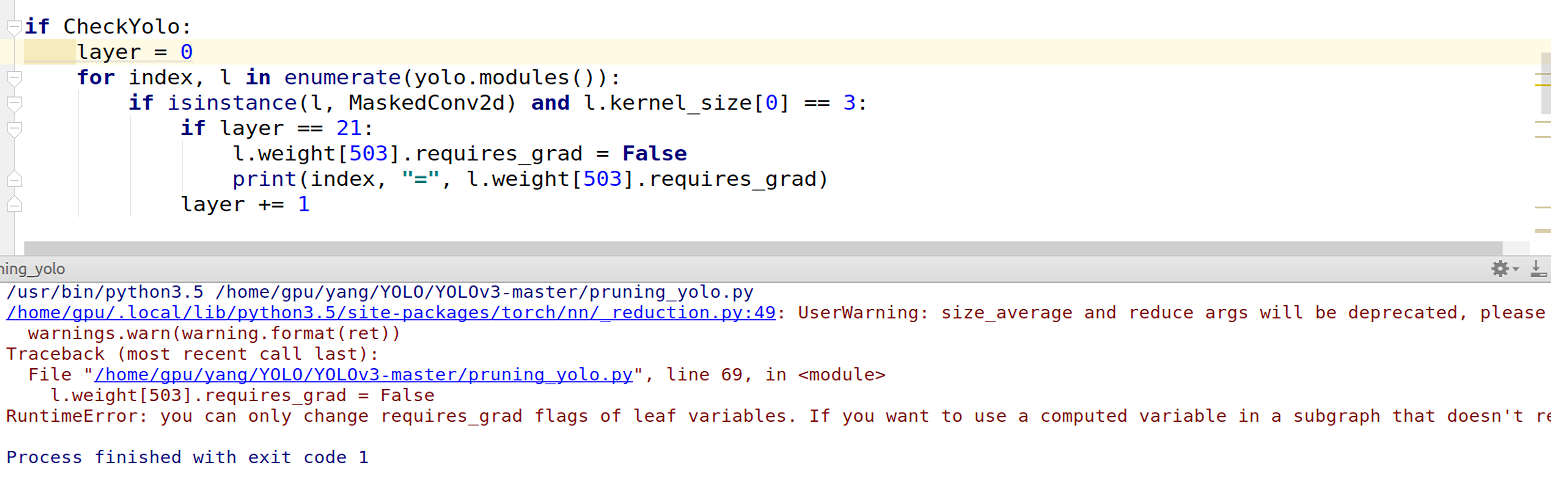
then retrain the model. but These cut weights are trained to be non-zero. I wanna freeze only zero weights in entire network. In this context, freeze means that freezed weights cannot be trained anymore. The following method is not feasible
It looks like you would like to set the requires_grad flag to False for a specific kernel of your weight matrix.
This is not possible as you can only set requires_grad for the whole matrix.
However, you could zero out the gradients for this kernel after backward and before the optimizer is called.
Hi ptrblck…can you please suggest which version of pytorch pruning will modify the architecture of the network,when filters are pruned?
I am currently using " nn.utils.prune" and is not removing the filters from original architecture.