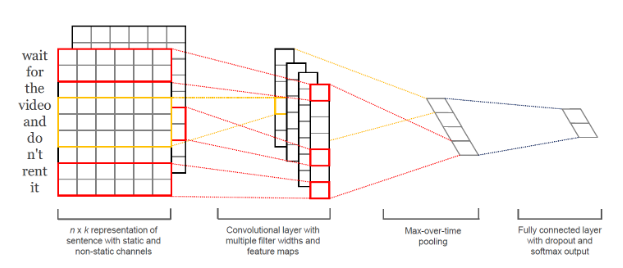
I’m struggling building a model for predicting rate of the movie with review as input.
I’ve preprocessed all my data and it’s shape is like below
v1 v2 v3 v4 .... vp
w1 1.1 0.2 0.1 2.1 x.xx
w2 … …
w3
w4
.
.
wl
each Wi represent tokenized word of the review and
V1~p represent the vector for the word.
So, know I’ve got every word represented 300 dimension vector.
For my model, I limited length of the sentence (the number of words in sentence) 140, so each review is represented as (140, 300) which is 140 words for each sentence and 300 size vector for one word.
Now here’s the problem
I’d like to design my model using 2d CNN as above, which will result in looking at 2 words each convolution.
How do I implement this?
I’m really confused with torch.nn.Conv2d’s parameters and struggling understanding it!
I am adding an example code. You have to implement convolutions of size (2Xembdedding_size) in your case 300. You can modify the below code for your case.
class Example(nn.Module):
def __init__(self, vocab_size, output_size, embedding_dim, drop_prob,n_filters,filter_sizes):
"""
Settin up the parameters.
"""
super(Intent_CNN, self).__init__()
self.output_size = output_size
# embedding layer and LSTM layers
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_size)
self.dropout = nn.Dropout(drop_prob)
def forward(self, x):
"""
Perform a forward pass
"""
#print("X initial",x.shape)
batch_size = x.size(0)
x = x.long()
#print("X long",x.shape)
embeds = self.embedding(x)
embedded = embeds.unsqueeze(1)
#print("embeds",embedded.shape)
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
#conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim = 1))
#cat = [batch size, n_filters * len(filter_sizes)]
out=self.fc(cat)
return out