Hi there, I’m testing with fp16 features of pytorch with a benchmark script provided here, getting these result(all with CUDA8 and cuDNN6):
➜ ~ python test_pytorch_vgg19_fp16.py
Titan X Pascal(Dell T630, anaconda2, pytorch 0.3.0):
FP32 Iterations per second: 1.7890313980917067
FP16 Iterations per second: 1.8345766566297141
Tesla P100(DGX-1, anaconda3, pytorch 0.3.0):
('FP32 Iterations per second: ', 2.001722807676548)
('FP16 Iterations per second: ', 1.9109340821222125)
Tesla P100(DGX-1, pytorch docker image provided by NVIDIA, pytorch 0.2.0):
FP32 Iterations per second: 1.9826932313239591
FP16 Iterations per second: 1.8854441494961636
For the detailed information of the docker image refer to here, it is theoretically optimized for DGX-1.
It can be seen that on P100 fp16 is even slower than fp32. Am I doing anything wrong? or PyTorch fp16 support is still under heavily developing? If so is there any doc for fp16 support status?
I would like to do more testing if needed, thanks a lot!
And another thanks for this great framework!
on P100 we dont expect FP16 to be any faster, because we disabled FP16 math on P100 (it is numerically unstable). We use simulated FP16, where storage is FP16, but compute is in FP32 (so it upconverts to FP32 before doing operations).
How about in 2080ti, I test a model trained in FP32 and using model.half() and input.half() in 2080TI with batch size fixed to 1, but do not see any speed up. But I noticed that the gpu memory usage is reduced by about 30%, why is that?Thanks.
What kind of operations are you using and which cudnn version in particular?
If you are using cudnn 7.3 and later, convolutions should use TensorCores for FP16 inputs.
GEMMs (e.g. used in linear layers) however have a size restriction of multiples of 8. For matrix A x matrix B, where A has size [I, J] and B has size [J, K], I, J, and K must be multiples of 8 to use TensorCores. This requirement exists for all cublas and cudnn versions.
Also, could you try to use torch.backends.cudnn.benchmark = True at the beginning of your script?
Operation contains maily conv2d and conv_transpose2d. I have set cudnn benchmark to true, but some of my matrix is not multiples of 8, I will try to change it then test. CUDA Version 9.2.148, cudnn 7.6.3.
Thank you very much.
this is the way, how I convert model fp32 to fp16 in mmdetection:
def wrap_fp16_model(model):
"""Wrap the FP32 model to FP16.
If you are using PyTorch >= 1.6, torch.cuda.amp is used as the
backend, otherwise, original mmcv implementation will be adopted.
For PyTorch >= 1.6, this function will
1. Set fp16 flag inside the model to True.
Otherwise:
1. Convert FP32 model to FP16.
2. Remain some necessary layers to be FP32, e.g., normalization layers.
3. Set `fp16_enabled` flag inside the model to True.
Args:
model (nn.Module): Model in FP32.
"""
if (TORCH_VERSION == 'parrots'
or digit_version(TORCH_VERSION) < digit_version('1.6.0')):
# convert model to fp16
model.half()
# patch the normalization layers to make it work in fp32 mode
patch_norm_fp32(model)
# set `fp16_enabled` flag
for m in model.modules():
if hasattr(m, 'fp16_enabled'):
m.fp16_enabled = True
def patch_norm_fp32(module):
"""Recursively convert normalization layers from FP16 to FP32.
Args:
module (nn.Module): The modules to be converted in FP16.
Returns:
nn.Module: The converted module, the normalization layers have been
converted to FP32.
"""
if isinstance(module, (nn.modules.batchnorm._BatchNorm, nn.GroupNorm)):
module.float()
if isinstance(module, nn.GroupNorm) or torch.__version__ < '1.3':
module.forward = patch_forward_method(module.forward, torch.half,
torch.float)
for child in module.children():
patch_norm_fp32(child)
return module
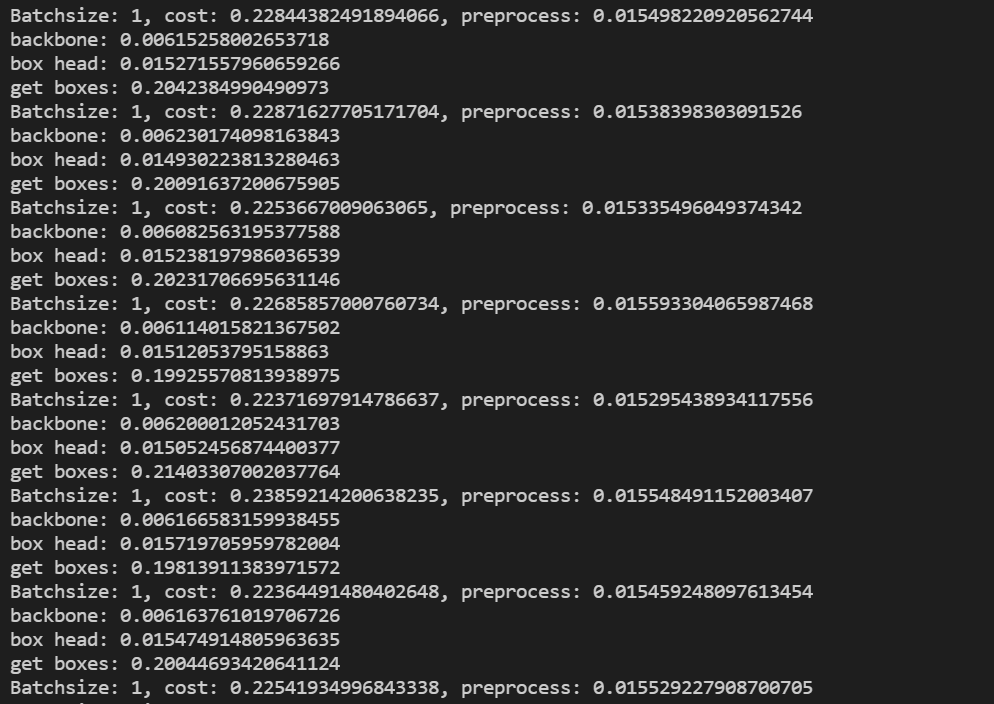
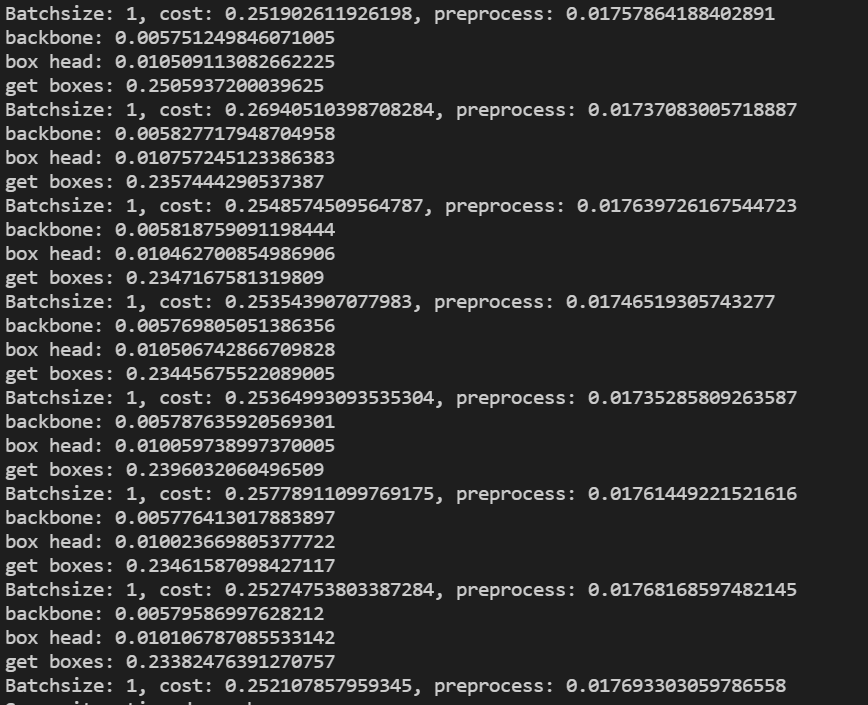
what is more importantly, for backbone and head, slower, but overall speed is faster…