I am attempting to produce a model that will accept multiple video frames as input and provide a label as output (a.k.a. video classification). I am new to this. I have seen code similar to the below in several locations for performing this tasks. I have a point of confusion however because the ‘out, hidden = self.lstm(x.unsqueeze(0))’ line out will ultimately only hold the output for the last frame once the for loop is completed, therefore the returned x at the end of the forward pass would be based solely on the last frame, right? What makes this architecture different than processing the last frame alone? Is a CNN-LSTM model an appropriate architecture for this type of problem in the first place? Thank you in advance for any insight you can offer my terribly confused brain!
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet101
class CNNLSTM(nn.Module):
def __init__(self, num_classes=2):
super(CNNLSTM, self).__init__()
self.resnet = resnet101(pretrained=True)
self.resnet.fc = nn.Sequential(nn.Linear(self.resnet.fc.in_features, 300))
self.lstm = nn.LSTM(input_size=300, hidden_size=256, num_layers=3)
self.fc1 = nn.Linear(256, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x_3d):
hidden = None
for t in range(x_3d.size(1)):
with torch.no_grad():
x = self.resnet(x_3d[:, t])
out, hidden = self.lstm(x.unsqueeze(0))
x = self.fc1(out.squeeze())
x = F.relu(x)
x = self.fc2(x)
return x
Is this your implementation? It looks a bit odd to me, particularly since
out, hidden = self.lstm(x.unsqueeze(0))
is called within the loop, seemingly for a single frame (instead of a sequence of frames).
I can’t be sure however, since I don’t know the shape and nature of x_3d. Right now my guts say the code is off :). In general, CNN+LSTM is a common architecture, though.
OK, then the code is indeed wrong, or at least not as intended…presumably :).
out, hidden = self.lstm(x.unsqueeze(0))
is applied to each frame. And since you don’t give the last hidden state, this call will always re-initialize the hidden state of the LSTM. In short, the network will forget / ignore all previous frames. You have 2 alternatives here. The maybe quickest would be to change the line to
out, hidden = self.lstm(x.unsqueeze(0), hidden)
that is, only for the first frame, when hidden is None, the hidden state of the LSTM layer will be initialized. For all other frames the previous hidden state will be used. Disclaimer: I haven’t checked the source code, but I assume that the hidden state will be initialized when hidden is None. If this throws an error, you need to manually initialize the hidden state of the LSTM layer.
The second alternative is to move the call of the LSTM layer outside the loop. It should crudely look like this (in a bit of untested pseudo code, just to get the idea):
hidden = None
seq = []
for t in range(x_3d.size(1)):
with torch.no_grad():
x = self.resnet(x_3d[:, t])
seq.append(x)
out, hidden = self.lstm(seq)
However, not that out now contains the hidden states for each frame, not just the last. Which means you would also need to change the subsequent line of code. The simplest way should be
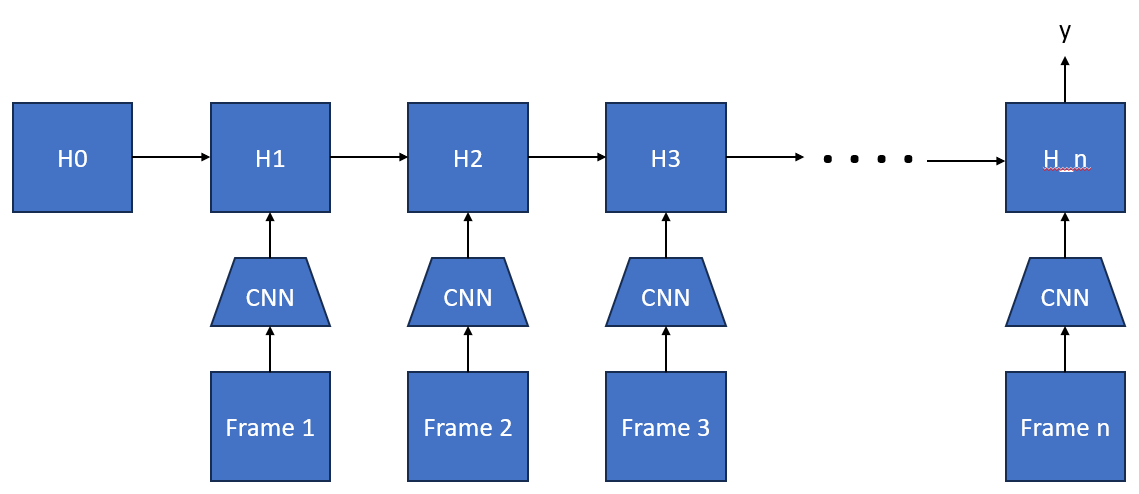
My understanding of the CNN+LSTM architecture is that you pass each frame through a CNN so you have latent representations of them, and then pass those latent representations through the LSTM to produce your final prediction (like the image below). Is there a typical architecture for this?
enables each subsequent frame to have knowledge of the prior frames because they all modify a “shared” hidden state. So then when I do my final classification, I would want to do it on that hidden state that all the frames had influenced
Exactly! This is the whole underlying concepts of Recurrent Neural Networks such as LSTMs and GRUs.
x = self.fc1(hidden[-1])
should also work if you leave the self.lstm call in the loop yes. The [-1] is to get the last hidden state with respect to the number of layers; and you have indeed 3 layers: num_layers=3
Yes, the architecture image you posted in your other reply is the basic CNN+LSTM setup.
Here is the updated version of the architecture for everyone’s benefit
class CNNLSTM(nn.Module):
def __init__(self, num_classes=2):
super(CNNLSTM, self).__init__()
self.resnet = resnet101(pretrained=True)
self.resnet.fc = nn.Sequential(nn.Linear(self.resnet.fc.in_features, 300))
self.lstm = nn.LSTM(input_size=300, hidden_size=256, num_layers=3)
self.fc1 = nn.Linear(256, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x_3d):
hidden = None
# Iterate over each frame of a video in a video of batch * frames * channels * height * width
for t in range(x_3d.size(1)):
with torch.no_grad():
x = self.resnet(x_3d[:, t])
# Pass latent representation of frame through lstm and update hidden state
out, hidden = self.lstm(x.unsqueeze(0), hidden)
# Get the last hidden state (hidden is a tuple with both hidden and cell state in it)
x = self.fc1(hidden[0][-1])
x = F.relu(x)
x = self.fc2(x)
return x
Hi, thanks for sharing the model code. May I know how you perform the training step for a batched input? Like, the loss computation and weights update.
The code I provided is set-up to accept batched inputs. It is expected that x_3d is in batch * frames * channels * height * width format. Therefore training follows the fairly typical prescribed format common for PyTorch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
loader = DataLoader(your_data)
model = CNNLSTM()
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr, momentum=momentum, weight_decay=weight_decay)
criterion = nn.MSELoss()
for e in range(100):
model.train()
for i, (X, y) in enumerate(loader):
optimizer.zero_grad()
X = X.to(device)
y = y.to(device)
yh = model(X)
yh = yh.flatten()
loss = criterion(yh, y)
loss.backward()
optimizer.step()
Thank you very much for the code, it has really helped someone like me in trying to implement a CNN+LSTM to my own work. I have a few questions as I’m trying to understand the CNN+LSTM workflow.
What is the output size of x after you call it? I’m having trouble understand what size the output should be in terms of batch size and sequence/frame length. If your batch size is 16 and your frame length is 30, should you return an output that is (16,30,1), or something else?
The output dimensions after you call CNNLSTM with a batch size of 16 would be (16, 2) under the default conditions, note that the last layer in the network is a linear layer that goes from 128 to 2. It “essentially” provides values that tell you how likely the network believes each of the 16 samples to belong to either class 1 or class 2. In most cases you will still want to run the output through a softmax function and then pick the index (1 or 2) with the maximal value to provide your final class prediction.
Note, the input dimensions (as I understand them from your example) would be (16, 30, 224, 224) which would be 16 samples, each with 30 frames, and each frame has a height and width of 224 (the expected size for the pytorch resnet101 models since I am using that in my network). If you are looking for a model that provides a prediction for each frame in each sample, i.e., your (16, 30, 1) output, you would require a different architecture than the one I have provided above.