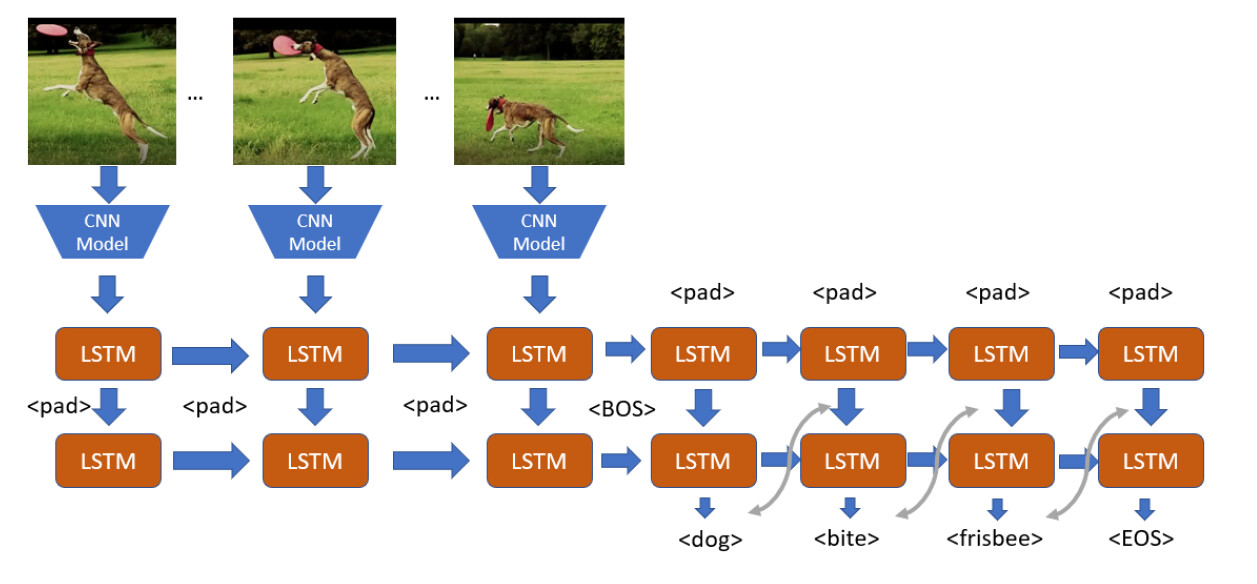
I have implemented a Cnn connected with an lstm to classify multi label videos with CTC Loss
I have two implementations as followed and I don’t know which is better for the forward/bakward operations and if there is any impact in training the network.
class TimeDistributed_Subunet(nn.Module):
def __init__(self,hidden_size,n_layers,dropt,bidirectional,N_classes ):
super(TimeDistributed_Subunet, self).__init__()
self.hidden_size = hidden_size
self.num_layers = n_layers
dim_feats = 4096
self.cnn = models.alexnet(pretrained=True)
self.cnn.classifier[-1] = Identity()
self.rnn = nn.LSTM(
input_size=dim_feats,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
dropout=dropt,
bidirectional=bidirectional)
self.n_cl = N_classes
if (bidirectional):
self.last_linear = nn.Linear(2 * self.hidden_size, self.n_cl)
else:
self.last_linear = nn.Linear(self.hidden_size, self.n_cl)
def forward(self, x):
batch_size, time_steps, C, H, W = x.size()
output = torch.tensor([])
output = output.to(x.get_device())
for i in range(time_steps):
cnn_out = self.cnn(x[:, i, :, :, :]).unsqueeze(0)
rnn_out,(hidden,cell_state) = self.rnn(cnn_out)
logits = self.last_linear(rnn_out)
output = torch.cat((output,logits),0)
return output
second implemenatation
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class SubUnet_orig(nn.Module):
def __init__(self,hidden_size,n_layers,dropt,bi,N_classes):
super(SubUnet_orig, self).__init__()
self.hidden_size=hidden_size
self.num_layers=n_layers
dim_feats = 4096
self.cnn=models.alexnet(pretrained=True)
self.cnn.classifier[-1]=Identity()
self.rnn = nn.LSTM(
input_size=dim_feats,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
dropout=dropt,
bidirectional=True)
self.n_cl=N_classes
if(True):
self.last_linear = nn.Linear(2*self.hidden_size,self.n_cl)
else:
self.last_linear = nn.Linear(self.hidden_size,self.n_cl)
def forward(self, x):
batch_size, timesteps, C,H, W = x.size()
c_in = x.view(batch_size * timesteps, C, H, W)
c_out = self.cnn(c_in)
r_out, (h_n, h_c) = self.rnn(c_out.view(-1,batch_size,4096))
r_out2 = self.last_linear(r_out)
return r_out2
The main difference is at the rnn where in the first implementation the cnn output for each timestep is passed inside a for loop to the rnn and in the other case the outputs for all timesteps are passed directly to the rnn