I am trying to identify 3 (classes) mental states based on EEG connectome data. The shape of the data is 99x1x34x 34x50x130, with respectably represent [subjects, channel, height, width, freq, time series]. For the sake of this study, can only input a 1x34x34 image of the connectome data. From previous studies, it was found that the alpha band (8-1 hz) had given the most information, thus the dataset was narrowed down to 99x1x34x34x4x130. The testing set accuracy on pervious machine learning techniques such as SVMs reached a testing accuracy of ~75%. Hence, by goal is to achieve a greater accuracy given the same data (1x34x34). Since my data is very limited 1-66 for training and 66-99 for testing (fixed ratios and have a 1/3 class distribution), I thought of splitting the data along the time series axis (6th axis) and then averaging the data to a shape of 1x34x34 (from ex. 1x34x34x4x10, 10 is the random sample of time series). This gave me ~1500 samples for training, and 33 for testing (testing is fixed, the class distributions are 1/3).
Results:
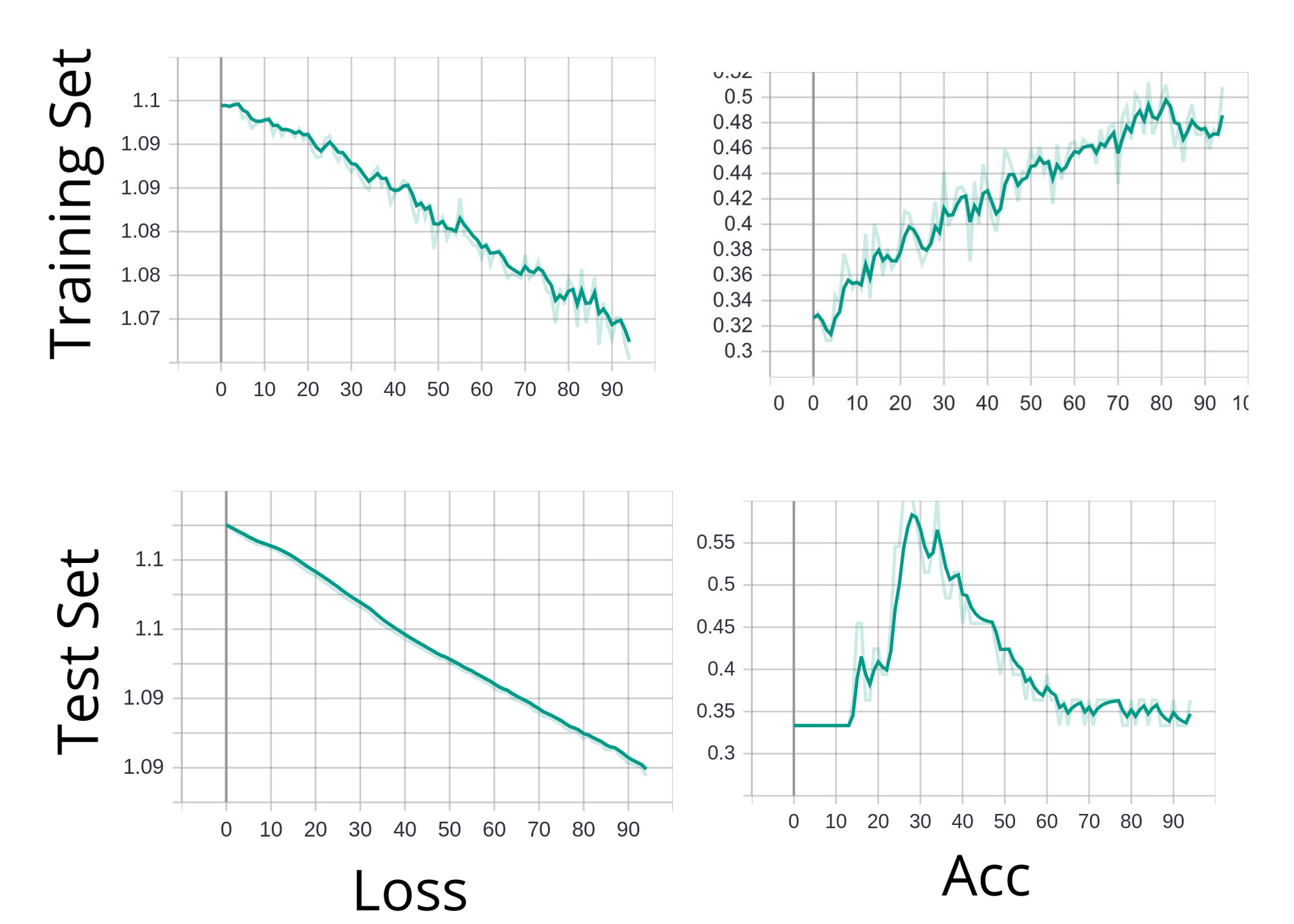
The training set can achieve an accuracy of 100% with enough iteration, but at the cost of the testing set accuracy. After around 20-50 epochs of testing, the model starts to overfit to the training set and the test set accuracy starts to decrease (same with loss).
What I have tried:
I have tried tuning the hyperparameters: lr=.001-000001, weight decay=0.0001-0.00001. Training to 1000 epochs (useless bc overfitting in less than 100 epochs). I have also tried increasing/decreasing the model complexity with adding adding addition fc layers and varying amount of channels in CNN layers form 8-64.
try these series of conv layers before pooling
next try one cycle scheduler
and still over fit try weight decay 0.01 ,if underfits decrease the weight decay
further if you are trying to classify between one of the 3 mental state , its right to use CrossEntropy
but if there can be more than one mental state classify as output , try using sigmoid
Thanks for the suggestions, I tried adding those CNN layers and the model did a bit worse averaging around an accuracy of ~45% on the test set. I tried manually scheduling the learning rate every 10 epochs, the results were the same. Weight decay didn’t seem to effect the results much, changed it from 0.1-0.000001.
From previous testing, I have a model that achieves 60% acc on both the testing and the training set. However, when I try to retrain it, the acc instantly goes down to ~40 on both sets (training and testing), which makes no sense. I have tried altering the learning rate from 0.01 to 0.00000001, and also tried weight decay for this.
From training the model and the graphs, it seems like the model dosn’t know what it’s doing for the first 5-10 epochs and then starts to learn rapidly to around ~50%-60% acc on both sets. This is where the model starts to overfit, form there the model’s acc increases to 100% on the training set, and the acc for the testing set goes down to 33%, which is equivalent to guessing.
Any other tips to improve acc for the testing set, and decrease overfitting?
It is only 1 channel, but LeNet-5’s structure is very similar to the structure that was previously suggested, but the image HxW is 32x32, whereas my image is 34x34 (and I can’t crop). Are there any other hyperparameters I should look into tuning? @ptrblck
Your test-set accuracy becomes significantly better than that of
your training set (before falling off again). While not mathematically
impossible, this is quite unlikely if your test and training set are both
representative of the same “universe” of data.
Also, your test-set loss falls steadily (similarly to, although not a low
as that of your training set). Although not the same, loss and
accuracy are related, so it’s surprising that your accuracy gets much
better, and then worse again, even as your loss is consistently falling.
(Again, not mathematically impossible, but unlikely.)
@KFrank
Thanks for your input! I do agree that accuracy data does look fishy, I am only a novice at deep learning and machine learning overall so I don’t have any ideas on how to check if the model is training correctly. The way my code is written, it checks the validation set every training batch, whereas the training set’s metrics are measured for every batch, thus the training batch’s acc/loss will fluctuate more than the test set’s (bc they are measured over the whole set and averaged, not recorded for each test batch). This only explains the fluctuation in the training set’s loss, and why its not in the testing set’s loss. Any tips?
I won’t guarantee it, but the results you posted look sufficiently odd
to me that I think it’s likely that you have a bug somewhere.
So, debugging …
Check intermediate results. Are they correct or do they at least make
sense?
See if you can simplify your code. Sometimes in the process, you’ll
recognize a bug. Or sometimes your simpler code will start working
the way you expect, and you can track down what change in the
simplification process caused things to work.
Review your code carefully, line by line. Is the calculation you are
doing one that makes sense? Are you actually doing the calculation
you think you are doing, or has a typo crept in somewhere?
Here is one specific consistency check I would suggest you make:
Since the oddness is in the comparison between your training and
test results, try running your test on a subset of your training data.
Instead of taking 33 test samples that are not part of your training
data, randomly select 33 of your 66 training samples and use them
for your test data.
But: Do everything else in your calculation exactly the same way.
Don’t change your code to make a quick hack to get the “test results”
from your training data – process your 33 “fake” samples exactly the
same way you process your real ones – any kind of preprocessing,
etc. Pass them through the exact same test-result evaluation code,
and so on.
Because you’re now running your “test” on training data, you shouldn’t
see any kind of overfitting. If you do, you’ll know that there’s a bug
somewhere.
The results do make sense the loss at least. Depending on the type of testing, I either use code that logs the data or just trains the model directly. Here is my simplified code (that I use and have found no errors or bugs in):
for epoch in t: # loop over the dataset multiple times
for i, data in enumerate(Htrainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs = inputs.to(device)
labels = (labels.to(device))
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Using this code with the check you suggested, I got the same results for accuracy, meaning the code is working correctly.
Note: this code is different than the code that was used to produce the image int the original post.
Anything else I can try? Other hyperparameter options?
But you’re talking about two different things here. The behavior of the
accuracy causes concern about overfitting. But then you say that the
loss makes sense – but, even if true, this ignores the accuracy issue.
And one of my concerns is that the behaviors of the loss and the
accuracy aren’t consistent with one another.
You’re trying to debug some code by running a consistency check on
it. But you actually run the consistency check on some different code.
Doing this kind of thing just confuses the issue.
Also, if we’re on the same page about the consistency check in
question, I don’t believe your result.
My complaint was that your test accuracy became significantly
better than your training accuracy (in your original graphs, around
epoch 30). You say with the consistency check you get the same
results for accuracy.
My suggestion was to use half of your training data (33 samples)
as your “test” data. Your training accuracy (on your 66 training
samples?) is about 40% at epoch 30. Does this mean that you were
so lucky as to select just the right set of 33 training samples for your
“test” set so that your test accuracy went up to about 55% at epoch 30?
This doesn’t make any sense. (What do you think would happen if you
tried the other 33 samples for your “test” set? Or used all 66 training
samples for your “test” set?)
You have an apparent inconsistency – and likely bug – staring you
in the face. Trying other hyperparameters at this point would just be
sweeping the issue under the rug.
Your right, I didn’t make the connection between test loss and accuracy. A quick google search results in some posts about similar issues, but offers no expiations as to how to solve it or what is causing it, only inferring that the model is overfitting.
The accuracy increased by around 20%, only for a few batches. I can only infer this is because the validation set only has 33 samples.
I double checked each line in my training class, couldn’t find anything. I trained on the MNIST dataset with my training class and the results look perfect.