I have a CNN acting as a regressor to predict a value between 0-1 for images where 1 represents a nice ordered disk looking object and 0 represents almost random disorderly moving object.
I have 1,525,760 images to train on but I’m restricting the number of samples selected per epoch to be 23840. This number was chosen because the batch size is 64 and it means that one new epoch under this sampling method is only 1/64th of a true epoch.
To do this I’m using WeightedRandomSampler with the weights of each image set equally to 1. In this respect, I believe that the CNN will draw purely random samples to make each new batch.
The reason I’m doing this is to observe how the data is fitting while seeing the images for the first time, as in tests with ordinary epochs I found the validation set to stagnate from epoch 1 onwards.
It looks like the validation loss drops and then stagnates before it hits the end of epoch one when using the new sampling system as seen below:
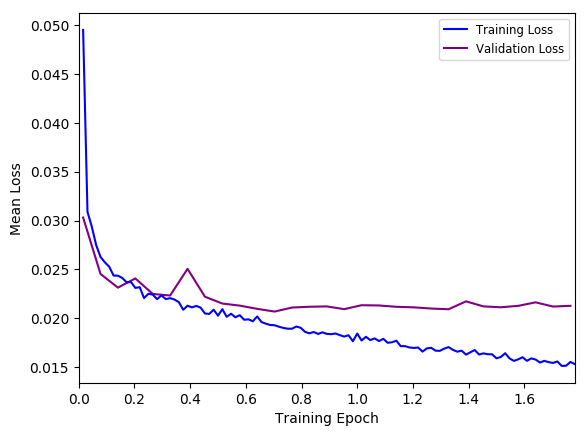
Please note that the Y-axis is MSE loss.
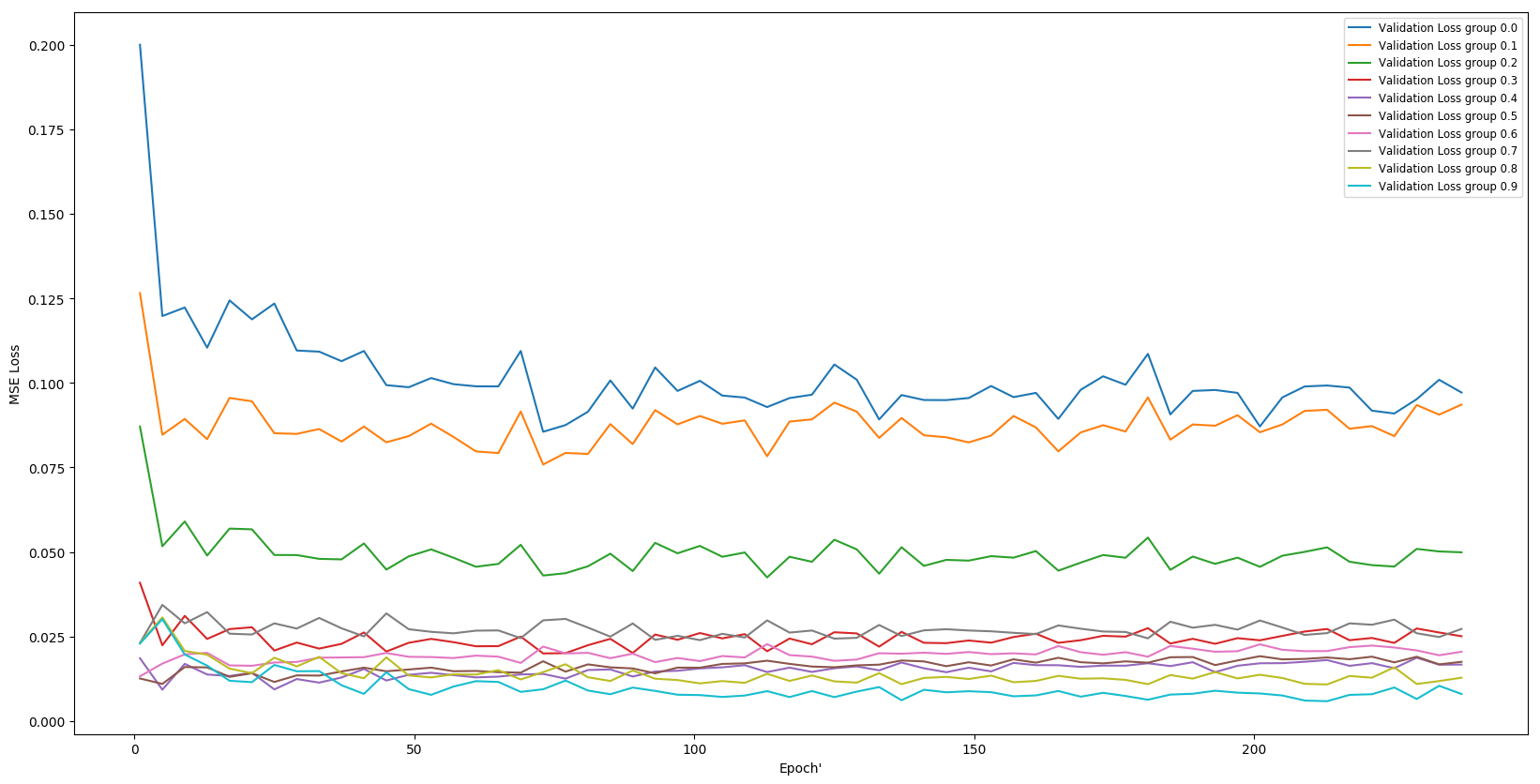
Perhaps the model is solving part of the regression problem (maybe the k=1 end which has lower diversity in image appearance) and then struggling on after that?
My question is:
Is there a way to improve the accuracy of the CNN before the stagnating validation accuracy.
Things to consider:
I don’t think this is classic overfitting as the CNN hasn’t seen all of the data by epoch 0.4 at which point the validation and training accuracy diverge.
I’ve tried using dropout in case it was overfitting but all that does is shift the training and validation curves higher in MSE loss.
My model:
class RegressionalNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.feature_extractor = torch.nn.Sequential(
torch.nn.Conv2d(1,64,3,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,3,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(128,256,3,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.classifier = torch.nn.Sequential(
torch.nn.Linear(256*16*16,256),
torch.nn.ReLU(),
torch.nn.Linear(256,256),
torch.nn.ReLU(),
torch.nn.Linear(256,256),
torch.nn.ReLU(),
torch.nn.Linear(256,1))
def forward(self,x):
features = self.feature_extractor(x)
output = self.classifier(features.view(int(x.size()[0]),-1))
return output
I am using:
Adam optimizer with initial learning rate = 1e-3
MSELoss
Any help would be greatly appreciated!