Hello all,
I tried to develop a CNN for regression problem.
Inputs and outputs dimensions are
# Test One Pass
xb, yb = next(iter(train_dl))
xb.shape, yb.shape
(torch.Size([10, 6, 40, 80]), torch.Size([10, 1, 40, 80]))
, and prediction’s dimension is
pred = unet(xb)
pred.shape
torch.Size([10, 1, 40, 80])
I modified the U-net, and I add Sigmoid at the final layer to provide the array predictions.
I also used “MSE” loss function for calculating the float tensor output losses.
Inputs and outputs are definitely different for all data points, but the final prediction values looks almost same for every data points likes below.
First six columns represent inputs (6 channels), and the 7th column is outputs (1 channel).
The 8th column is predicted tensors.
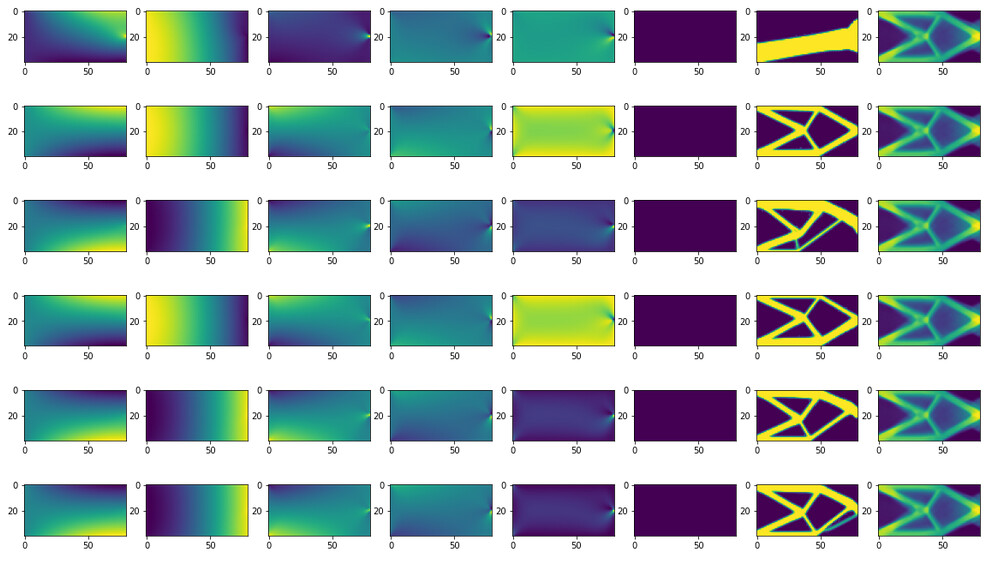
I think this problem is coming from my CNN structures or training process.
I attached my code sets.
If you have any suggestions or find reasons, please let me know.
I really appreciate your time for reading my post. Thank you!
Modified Unet:
# Class for U-Net
from torch import nn
class UNET(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = self.contract_block(in_channels, 32, 7, 3)
self.conv2 = self.contract_block(32, 64, 3, 1)
self.conv3 = self.contract_block(64, 128, 3, 1)
self.upconv3 = self.expand_block(128, 64, 3, 1)
self.upconv2 = self.expand_block(64*2, 32, 3, 1)
self.upconv1 = self.expand_block(32*2, 32, 3, 1)
self.postconv = self.post_block(32, out_channels, 7,3)
def __call__(self, x):
# downsampling part
conv1 = self.conv1(x)
conv2 = self.conv2(conv1)
conv3 = self.conv3(conv2)
upconv3 = self.upconv3(conv3)
upconv2 = self.upconv2(torch.cat([upconv3, conv2], 1))
upconv1 = self.upconv1(torch.cat([upconv2, conv1], 1))
postconv = self.postconv(upconv1)
return postconv
def post_block(self, in_channel, out_channel, kernel_size, padding):
# sigmoid for final output
post = nn.Sequential(
torch.nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, stride =1, padding=padding),
torch.nn.BatchNorm2d(in_channel),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, stride =1, padding=padding),
torch.nn.BatchNorm2d(in_channel),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride =1, padding=padding),
torch.nn.Sigmoid()
)
return post
def contract_block(self, in_channels, out_channels, kernel_size, padding):
contract = nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=1, padding=padding),
torch.nn.BatchNorm2d(out_channels),
torch.nn.ReLU(),
torch.nn.Conv2d(out_channels, out_channels, kernel_size=kernel_size, stride=1, padding=padding),
torch.nn.BatchNorm2d(out_channels),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
return contract
def expand_block(self, in_channels, out_channels, kernel_size, padding):
expand = nn.Sequential(torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=padding),
torch.nn.BatchNorm2d(out_channels),
torch.nn.ReLU(),
torch.nn.Conv2d(out_channels, out_channels, kernel_size, stride=1, padding=padding),
torch.nn.BatchNorm2d(out_channels),
torch.nn.ReLU(),
torch.nn.ConvTranspose2d(out_channels, out_channels, kernel_size=3, stride=2, padding=1, output_padding=1)
)
return expand
Training Process:
import time
from IPython.display import clear_output
def train(model, train_dl, valid_dl, loss_fn, optimizer, acc_fn, epochs=1):
start = time.time()
model.to(DEVICE)
train_loss, valid_loss = [], []
best_acc = 0.0
for epoch in range(epochs):
print('Epoch {}/{}'.format(epoch, epochs - 1))
print('-' * 10)
for phase in ['train', 'valid']:
if phase == 'train':
model.train(True) # Set trainind mode = true
dataloader = train_dl
else:
model.train(False) # Set model to evaluate mode
dataloader = valid_dl
running_loss = 0.0
running_acc = 0.0
step = 0
# iterate over data
for x, y in dataloader:
x = x.to(DEVICE)
y = y.to(DEVICE)
step += 1
# forward pass
if phase == 'train':
# zero the gradients
optimizer.zero_grad()
outputs = model(x)
loss = loss_fn(outputs, y)
# the backward pass frees the graph memory, so there is no
# need for torch.no_grad in this training pass
loss.backward()
optimizer.step()
# scheduler.step()
else:
with torch.no_grad():
outputs = model(x)
loss = loss_fn(outputs, y)
# stats - whatever is the phase
acc = acc_fn(outputs, y)
running_acc += acc*dataloader.batch_size
running_loss += loss*dataloader.batch_size
if step % 10 == 0:
# clear_output(wait=True)
print('Current step: {} Loss: {} Acc: {} AllocMem (Mb): {}'.format(step, loss, acc, torch.cuda.memory_allocated()/1024/1024))
# print(torch.cuda.memory_summary())
epoch_loss = running_loss / len(dataloader.dataset)
epoch_acc = running_acc / len(dataloader.dataset)
clear_output(wait=True)
print('Epoch {}/{}'.format(epoch, epochs - 1))
print('-' * 10)
print('{} Loss: {:.4f} Acc: {}'.format(phase, epoch_loss, epoch_acc))
print('-' * 10)
train_loss.append(epoch_loss) if phase=='train' else valid_loss.append(epoch_loss)
time_elapsed = time.time() - start
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
return train_loss, valid_loss
def acc_metric(predb, yb):
return (predb.argmax(dim=1) == yb.cuda()).float().mean()