Hi folks, ![]()
i am working on a face expression recognition project and i am using the public dataset fer2013 (with its original data splits:
abt 28,709 training set, 3,589 validation set and 3,589 test set). As input for my CNN i get scaled (from 0-1) grey-scale 48x48 face
images and for output i get a tensor which gives 7 probability values for each 7 emotions (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)
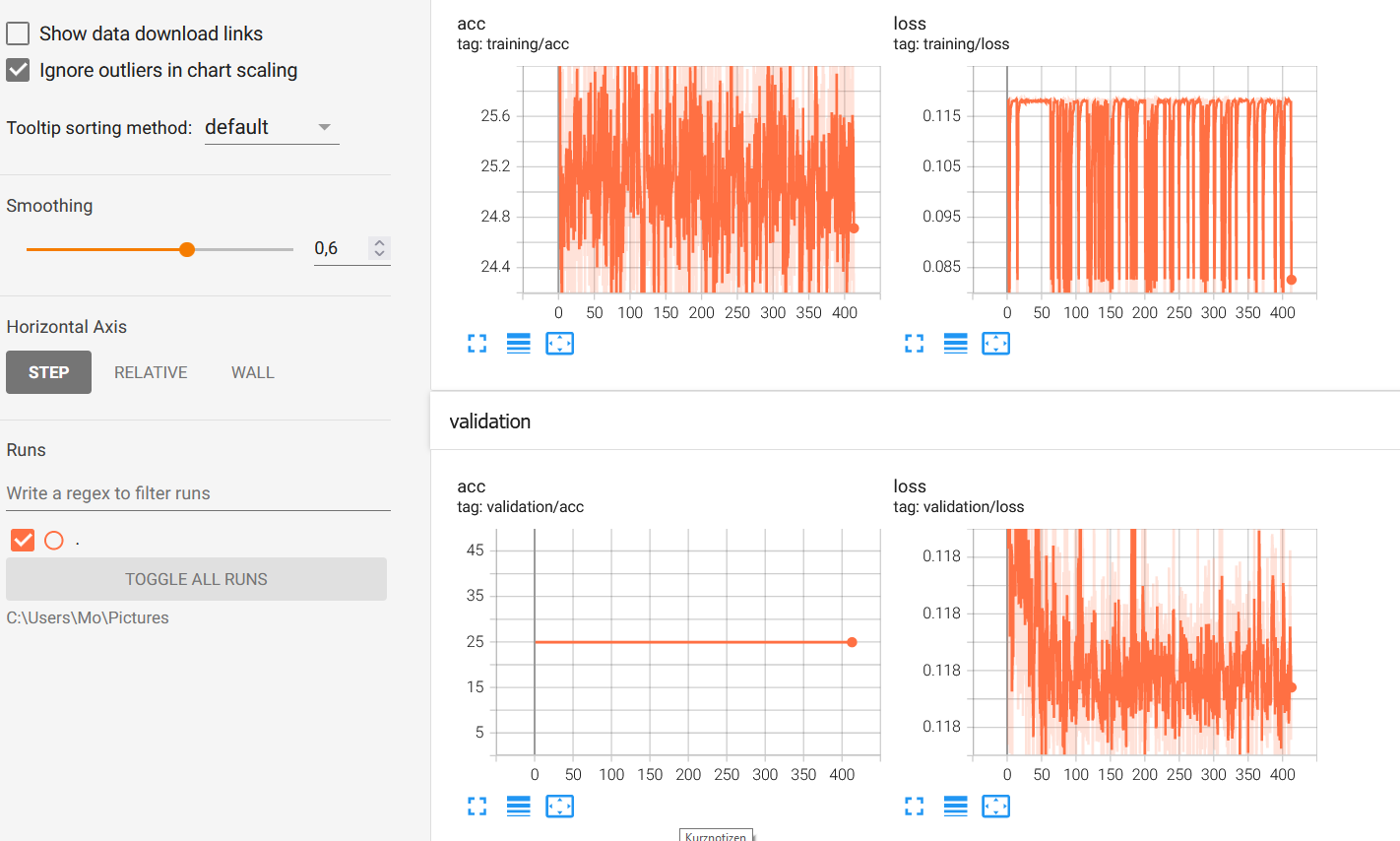
After i have trained my CNN model for about 400 epochs while printing the running training loss/acc over every 20 mini-batches and also validating
on the whole validation dataset after every 20 mini-batches, i see that my validation accuracy is just staying at that same exact value
of 24,94 even after running 400 epochs…Also the validation loss is not moving that much…At this point i have no idea what exactly i am doing wrong.
Is my evaluation method, which i call for validation even correct? Is the way i am calculating loss and accuracy correct?
Why is my validation loss/acc staying at the same value and not improving?
I would be really greatful for ANY help or improvement suggestions. ![]()
![]()
![]()
I have the following configurations:
“device”: “cuda:0”,
“learningrate”: 1e-3,
“weight_decay”: 1e-5,
“epochs”: 500,
IMAGE_SIZE = 48
BATCH_SIZE = 128
MY CNN-MODEL----------------------------------------------------------------------------------
class CustomCNN(nn.Module):
def __init__(self, drop=0.5, n_in_channels: int = 1, n_kernels: int = 64,
kernel_size: int = 3):
super().__init__()
padding = int(kernel_size / 2)
self.conv1a = nn.Conv2d(in_channels=n_in_channels, out_channels=n_kernels, kernel_size=kernel_size, padding=1)
self.conv1b = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=kernel_size, padding=1)
self.conv2a = nn.Conv2d(in_channels=64, out_channels=96, kernel_size=kernel_size, padding=padding)
self.conv2b = nn.Conv2d(in_channels=96, out_channels=96, kernel_size=kernel_size, padding=padding)
self.conv3a = nn.Conv2d(96, 128, kernel_size=kernel_size, padding=padding)
self.conv3b = nn.Conv2d(128, 128, kernel_size=kernel_size, padding=padding)
self.conv4a = nn.Conv2d(128, 256, kernel_size=kernel_size, padding=padding)
# max pooling right here
self.conv4b = nn.Conv2d(256, 256, kernel_size=kernel_size, padding=padding)
self.bn1a = nn.BatchNorm2d(64)
self.bn1b = nn.BatchNorm2d(64)
self.bn2a = nn.BatchNorm2d(96)
self.bn2b = nn.BatchNorm2d(96)
self.bn3a = nn.BatchNorm2d(128)
self.bn3b = nn.BatchNorm2d(128)
self.bn4a = nn.BatchNorm2d(256)
self.bn4b = nn.BatchNorm2d(256)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=1)
self.drop = nn.Dropout(p=drop)
self.relu = nn.ReLU() # torch.nn.LeakyReLU(0.3)
''' passing random data through model just to get shape of last conv2d output'''
self._to_linear = None
x = torch.randn(48, 48).view(-1, 1, 48, 48)
self.convs(x)
self.lin1 = nn.Linear(self._to_linear, 256)
self.lin3 = nn.Linear(256, 7)
def convs(self, x):
x = self.relu(self.bn1a(self.conv1a(x)))
x = self.relu(self.bn1b(self.conv1b(x)))
x = self.pool(x) # from 48x48 to 24x24
x = self.relu(self.bn2a(self.conv2a(x)))
x = self.relu(self.bn2b(self.conv2b(x)))
x = self.pool(x) # from 24x24 to 12x12
x = self.relu(self.bn3a(self.conv3a(x)))
x = self.relu(self.bn3b(self.conv3b(x)))
x = self.pool(x) # from 12x12 to 6x6
x = self.relu(self.bn4a(self.conv4a(x)))
x = self.pool2(x) # max pool from 6x6 to 4x4
x = self.relu(self.bn4b(self.conv4b(x)))
if self._to_linear is None:
self._to_linear = x[0].shape[0] * x[0].shape[1] * x[0].shape[2]
return x
def forward(self, x):
x = self.convs(x)
x = x.view(-1, self._to_linear)
x = F.relu(self.lin1(x))
x = self.lin3(x)
return F.softmax(x, dim=1)
function for validating / evaluating model-------------------------------------------------------------------------------------
def evaluate(model: nn.Module, loader: DataLoader, loss_fn):
model.eval()
device = next(model.parameters()).device
loss_avg, correct_predictions = 0.0, 0.0
nr_samples = len(loader.dataset)
with torch.no_grad():
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = loss_fn(outputs, labels)
# calculating some performance metrics
loss_avg += loss.item()
correct_predictions += outputs.argmax(dim=1).eq(labels.argmax(dim=1)).sum().item()
accuracy = 100 * (correct_predictions / nr_samples)
loss = loss_avg / nr_samples
return accuracy, loss
----main-----------------------------------------------------------------------------------------------------------------------
“”“Main function that takes hyperparameters and performs training and evaluation of model”“”
def main(results_path, network_config: dict, learningrate: int = 1e-3, weight_decay: float = 1e-5,
epochs: int = 400, device: torch.device = torch.device("cuda:0")): # cuda:0
training_dataset = ImageDataset(TRAINING_DATA, TRAINING_LABELS)
val_dataset = ImageDataset(VAL_DATA, VAL_LABELS)
test_dataset = ImageDataset(TEST_DATA, TEST_LABELS)
trainloader = torch.utils.data.DataLoader(training_dataset, batch_size=1, shuffle=False, num_workers=0)
valloader = torch.utils.data.DataLoader(val_dataset, batch_size=1, shuffle=False, num_workers=0)
testloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=0)
trainloader_augmented = torch.utils.data.DataLoader(training_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=1)
writer = SummaryWriter(log_dir=os.path.join(results_path, "tensorboard", "experiments", "2k_run"))
print_stats_at = 20 # print status to tensorboard every x batch e.g after every 5 batches
validate_at = 20 # evaluate model on validation set and check for new best model every x batches
update = 0 # current update counter
best_validation_loss = np.inf # best validation loss so far
update_progess_bar = tqdm.tqdm(total=epochs, desc=f"loss: {np.nan:7.5f}", position=0) # progressbar
model = CustomCNN()
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learningrate, weight_decay=weight_decay)
loss_fn = MSELoss()
running_loss, correct_predictions = 0.0, 0.0
nr_samples = 0
model.train()
# Train until n epochs have been reached
'''
reporting an averaged loss over N(print_Stats_at) mini-batches, where N is large enough to
smooth out the noise of individual batches but not so large that the model
performance is not comparable between the first and last batches.
'''
print(datetime.now(), " Training started.")
while update < epochs:
for i, data in enumerate(trainloader_augmented):
inputs, targets = data
inputs, targets = inputs.to(device), targets.to(device)
# Reset gradients
nr_samples += inputs.size(0)
optimizer.zero_grad()
outputs = model(inputs)
# Calculate loss, do backward pass, and update weights
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
correct_predictions += outputs.argmax(dim=1).eq(targets.argmax(dim=1)).sum().item()
running_loss += loss.item()
if i % print_stats_at == 0 and update > 0: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(update + 1, i + 1, running_loss / print_stats_at))
print('[%d, %5d] acc: %.3f' %
(update + 1, i + 1, 100 * (correct_predictions / nr_samples)))
writer.add_scalar(tag="training/loss",
scalar_value=running_loss / print_stats_at,
global_step=update)
writer.add_scalar(tag="training/acc",
scalar_value=100 * (correct_predictions / nr_samples),
global_step=update)
running_loss = 0.0
correct_predictions = 0.0
nr_samples = 0
if i % validate_at == 0 and update > 0:
val_acc, val_loss = evaluate(model, valloader, loss_fn)
print('[%d, %5d] val acc: %.3f' % (update + 1, i + 1, val_acc))
print('[%d, %5d] val loss: %.3f' % (update + 1, i + 1, val_loss))
print("------------------------------")
writer.add_scalar(tag="validation/loss", scalar_value=val_loss, global_step=update)
writer.add_scalar(tag="validation/acc", scalar_value=val_acc, global_step=update)
# Save best model for early stopping
if best_validation_loss > val_loss:
best_validation_loss = val_loss
torch.save(model, os.path.join(results_path, f'best_{MODEL_PATH}'))
update_progess_bar.set_description(f"avg_loss: {running_loss:7.5f}", refresh=True)
update_progess_bar.update()
update += 1
if update >= epochs:
break
writer.flush() #method to make sure that all pending events have been written to disk.
writer.close()
update_progess_bar.close()
print(f"{datetime.now()}: Finished Training!")