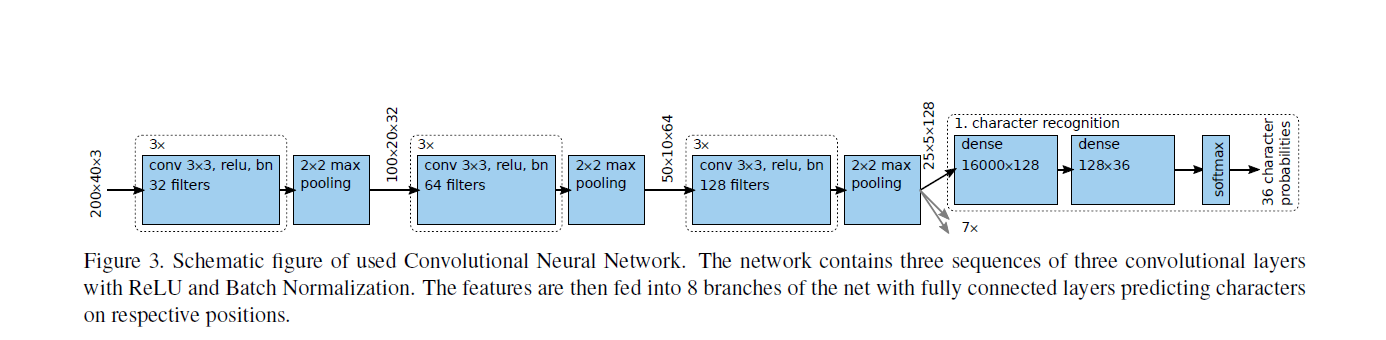
How exactly are batches processed in one iteration? For example, I have built a network that accepts an image and outputs 8 sets of values, having 36 probability distributed values each for each item of the set. So the total number of outputs for a single image is 8x36 = 288. So, my model actually returns 8 tensor values (x1,x2,…x8) at the end of the forward function having a size of [1,36]. Now, since I am working with batches, I am getting confused with the actual processing of each image in each iteration.
Suppose the batch size is set to 10. Now, the network will be given a batch of 10 images at once. Now, will the network process all the 10 images at once or does it take 1 image at a time, produce the result and then take another one and so on until all ten images are processed and then calculate the value and returns them? If it takes 8 images at once and processes them all at once, then the network is supposed to give me (batches x no of sets of values x no of probability distributed values in each set) = 10 x 8 x 36 = 2880 values, but as the network is designed to give 8 tensors of [1,36] size, how am I losing other values in the process? For reference, I am sharing the network architecture as well as the training loops for the same. Also, I am attaching the architecture that I am trying to mimic.
Network Architecture:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3)
self.conv1a = nn.Conv2d(16, 16, 3)
self.batch1 = nn.BatchNorm2d(16)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 3)
self.conv2a = nn.Conv2d(32, 32, 3)
self.batch2 = nn.BatchNorm2d(32)
self.pool2 = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(32, 64, 3)
self.conv3a = nn.Conv2d(64, 64, 3)
self.batch3 = nn.BatchNorm2d(64)
self.pool3 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(84672, 128)
self.fc2 = nn.Linear(128, 36)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = F.relu(self.batch1(self.conv1(x)))
x = F.relu(self.batch1(self.conv1a(x)))
x = self.pool1(x)
x = F.relu(self.batch2(self.conv2(x)))
x = F.relu(self.batch2(self.conv2a(x)))
x = self.pool2(x)
x = F.relu(self.batch3(self.conv3(x)))
x = F.relu(self.batch3(self.conv3a(x)))
x = self.pool3(x)
x = x.view(-1,84672)
x1 = F.relu(self.fc1(x))
x1 = F.relu(self.fc2(x1))
x1 = self.softmax(x1)
x2 = F.relu(self.fc1(x))
x2 = F.relu(self.fc2(x2))
x2 = self.softmax(x2)
x3 = F.relu(self.fc1(x))
x3 = F.relu(self.fc2(x3))
x3 = self.softmax(x3)
x4 = F.relu(self.fc1(x))
x4 = F.relu(self.fc2(x4))
x4 = self.softmax(x4)
x5 = F.relu(self.fc1(x))
x5 = F.relu(self.fc2(x5))
x5 = self.softmax(x5)
x6 = F.relu(self.fc1(x))
x6 = F.relu(self.fc2(x6))
x6 = self.softmax(x6)
x7 = F.relu(self.fc1(x))
x7 = F.relu(self.fc2(x7))
x7 = self.softmax(x7)
x8 = F.relu(self.fc1(x))
x8 = F.relu(self.fc2(x8))
x8 = self.softmax(x8)
return x1,x2,x3,x4,x5,x6,x7,x8
Training iteration:
steps = 0
print_every = 50
for e in range(30):
running_loss = 0
for batch_i, data in enumerate(train_loader):
steps += 1 # Forward pass
images = images.to(device)
labels = labels.view(labels.size(0), -1)
labels = labels.to(device)
#label1,label2,label3,label4,label5,label6,label7,label8 = labels <--------
optimizer.zero_grad()
x1,x2,x3,x4,x5,x6,x7,x8 = net(images)
x1 = criterion(x1, labels1)
x2 = criterion(x2, labels2)
x3 = criterion(x3, labels3)
x4 = criterion(x4, labels4)
x5 = criterion(x5, labels5)
x6 = criterion(x6, labels6)
x7 = criterion(x7, labels7)
x8 = criterion(x8, labels8)
loss = x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8
loss.backward() # Backward pass
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
with torch.no_grad():
model.eval()
for images, labels in enumerate(test_loader):
images = data['image'].to(device)
labels = data['lpno'].to(device)
images = images.to(device)
labels = labels.view(labels.size(0), -1)
labels = labels.to(device)
log_ps = net(images)
test_loss += criterion(log_ps, labels)
ps = torch.exp(log_ps)
top_p, top_class = ps.topk(1, dim = 1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor))
model.train()
trainLoss.append(running_loss/len(train_loader))
testLoss.append(test_loss/len(test_loader))
print("Epoch: {}/{}.. ".format(e + 1, epochs),
"Test Accuracy: {:.3f}".format(accuracy/len(test_loader)))
For the calculation of the loss, I need to get labels1 to labels8 values but that could be only possible if I somehow know how batches of input get processed.
Architecture that I want to mimic: