I’m really excited to try out the latest pytorch build (1.12.0.dev20220518) for the m1 gpu support, but on my device (M1 max, 64GB, 16-inch MBP), the training time per epoch on cpu is ~9s, but after switching to mps, the performance drops significantly to ~17s. Is that something we should expect, or did I just mess something up?
BTW, there were failed assertions that may relate to mps as well, the traceback is as follows
/AppleInternal/Library/BuildRoots/560148d7-a559-11ec-8c96-4add460b61a6/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm:343: failed assertion `unsupported datatype for constant'
Aborted
/opt/homebrew/Cellar/python@3.10/3.10.4/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
What were the data types of the tensors you were using? Could you show us the script? I have a good idea of which data types MPS and MPSGraph supports. Also, I think I have seen some peculiarities with MPSGraph’s internal MLIR compiler, which might cause a crash.
@albanD could you check out the memory management issue in the above comment’s log? I have previously seen apps crash when you don’t balance a DispatchSemaphore before releasing it. Maybe that’s an iOS-specific crash, but it should be standard practice to balance semaphore objects when using Foundation.
the training time per epoch on
cpuis ~9s, but after switching tomps, the performance drops significantly to ~17s.
If you happen to be using all CPU cores on the M1 Max in cpu mode, then you have 2.0 TFLOPS of processing power (256 GFLOPS per core) for matrix multiplication. On GPU, you have a maximum of 10.4 TFLOPS, although 80% of that is used. If a certain tensor shape works better on the CPU than the GPU, then the slowdown you experienced might be possible.
Hey!
Thanks for the report.
- For the datatype crash. You might want to make sure you’re not using
float64numbers next to the place where the crash happens as these are not supported for Tensors on mps. - For the slowdown, that is not expected for sure (but can happen depending on the workload as GPUs require large relatively large tasks to see speedups). If you have a simple repro for us to run locally, that would be very helpful!
For a more extensive list of which data types do and don’t run:
- Avoid Float64 on all Apple devices. Even if the hardware supports
Doublephysically (AMD or Intel), the Metal API doesn’t let you access it. - Avoid BFloat16. That is natively supported by the latest Nvidia GPUs, but not supported in Metal. Also don’t try to use TF18/TF32 or Int4.
- All standard integer types (UInt8, UInt16, UInt32, UInt64) and their signed counterparts work natively on Apple devices. Not exactly 8-bit integers, which are cast to 16-bit integers before being stored into registers, but those aren’t going to harm performance. Yes, they run 64-bit integers on the Apple GPU and not 64-bit floats. Metal allows you to use 64-bit integers in shaders on AMD and Intel, but the arithmetic there might just happen through emulation (slow). I think that’s where I experienced the crash in MPSGraph previously - trying to run an operation on UInt64 on my Intel Mac mini.
For anything else regarding compatibility of data types, the Metal feature set tables might be useful:
2 Likes
I remember the crash with MPSGraph more precisely. I was messing around with transcendental functions while prototyping an S4TF Metal backend, and had a configuration where I passed a UInt64 MPSGraphTensor into a function that normally runs with floating point in hardware. They would have to convert the integer to a float before actually running the operation. It worked for everything up to 32-bit integers, but I made a special configuration using 64-bit integers that broke the MLIR compiler. The error message was something like “pow_u64 not found”. You may need to watch out for a bug like this as well as Float64 crashes.
Here are all the code that I use to test, download and just run CNN.py should work. I think that I’m indeed using the Float64 datatype, which is the default I think? I’ll try using another datatype later.
Sorry that I can only put up to 2 links in a post. so here is another half of the code
How about torch.bool? Bool seems to be unsupported but it’s such a common data type.
import torch
t = torch.ones(1, device=torch.device('mps'))
m = t.ne(0)
m[0] = False
print(m)
/AppleInternal/Library/BuildRoots/560148d7-a559-11ec-8c96-4add460b61a6/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm:343: failed assertion `unsupported datatype for constant’
A two second test, and you’re correct. Bool is not supported as an MPSGraph constant. That’s very wierd. I can’t say the same about other tensor types though, such as ones doing logical OR and what not. It shouldn’t be hard to figure that out, though.
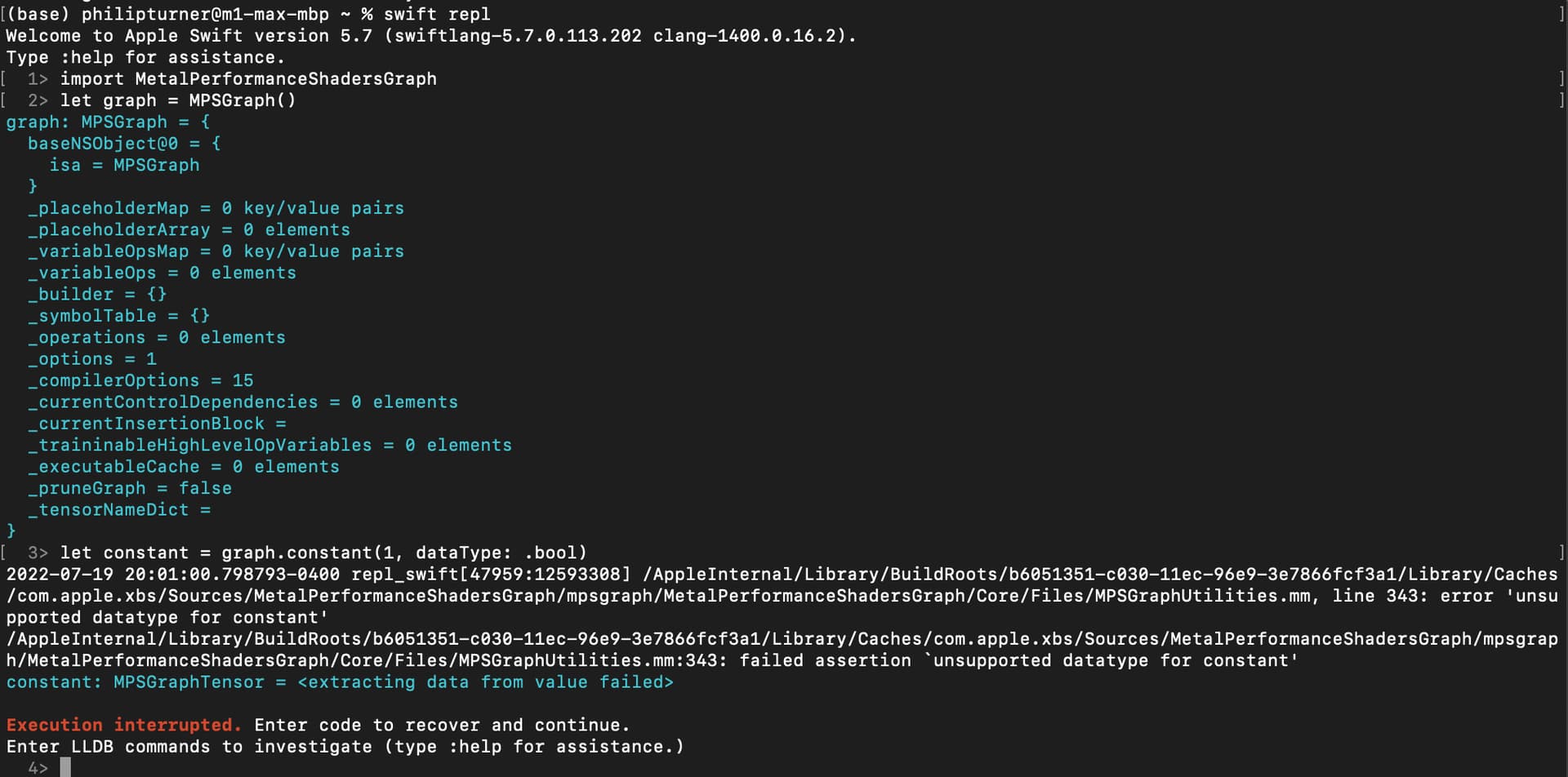
Yeah, this test case failed too on torch 1.13.0.dev20220719, here is a quick fix to the problem I think
import torch
T = torch.ones(1, device=torch.device('mps'))[0]
F = torch.zeros(1, device=torch.device('mps'))[0]
print(f"{T=}, {F=}")
t = torch.ones(1, device=torch.device('mps'))
m = t.ne(0)
print(m)
m[0] = F
print(m)
And I got the expected output like below, though a fall back warning was triggered
T=tensor(1., device='mps:0'), F=tensor(0., device='mps:0')
tensor([True], device='mps:0')
tensor([False], device='mps:0')
Edit:
I think the problem is that you cannot assign any value to such a tensor on mps device, so conversion before doing so is needed to get things done.
Here’s a deep investigation into the nature of the problem. I lowered the Python code into its respective calls to Metal. I’m writing the script in Swift because I’m most familiar with that language, but I hope you can follow along. I explicitly marked which code sections correspond to the Python code using // PYTHON CODE:
The script is large, so you may have to scroll to see all of it.
import MetalPerformanceShadersGraph
func testTensor0D(_ torchValue: Double) -> Float {
let graph = MPSGraph()
let tensor = graph.constant(torchValue, dataType: .float32)
let data = graph.run(
feeds: [:], targetTensors: [tensor], targetOperations: nil)[tensor]
let ndarray = data!.mpsndarray()
var output: [Float32] = .init(repeating: 9999, count: 1)
ndarray.readBytes(&output, strideBytes: nil)
return output.first!
}
// PYTHON CODE: T = torch.ones(1, device=torch.device('mps'))[0]
let T = testTensor0D(1.0)
// PYTHON CODE: F = torch.zeros(1, device=torch.device('mps'))[0]
let F = testTensor0D(0.0)
// PYTHON CODE: print(f"{T=}, {F=}")
print("T=\(T), F=\(F)")
extension MTLBuffer {
func setFirstElement(to value: Float32) {
let pointer = self.contents().assumingMemoryBound(to: Float32.self)
pointer[0] = value
}
func extractFirstElement() -> Float32 {
let pointer = self.contents().assumingMemoryBound(to: Float32.self)
return pointer[0]
}
}
func get_m_MTLBuffer() -> MTLBuffer {
let device: MTLDevice = MTLCreateSystemDefaultDevice()!
let commandQueue: MTLCommandQueue = device.makeCommandQueue()!
let graph = MPSGraph()
// PYTHON CODE: t = torch.ones(1, device=torch.device('mps'))
let t = graph.constant(1, dataType: .float32)
let zeroLiteral = graph.constant(0, dataType: .float32)
// PYTHON CODE: m = t.ne[0]
let m_Tensor: MPSGraphTensor = graph.notEqual(t, zeroLiteral, name: nil)
// Execute the MPSGraph.
let m_MTLBuffer = device.makeBuffer(
length: 1 * MemoryLayout<Float32>.stride, options: .storageModeShared)!
m_MTLBuffer.setFirstElement(to: 9999)
let m_TensorData = MPSGraphTensorData(
m_MTLBuffer, shape: [1], dataType: .float32)
graph.run(
with: commandQueue, feeds: [:], targetOperations: nil,
resultsDictionary: [m_Tensor: m_TensorData])
return m_MTLBuffer
}
do {
// Metal backing buffer that stores the tensor's data.
let m: MTLBuffer = get_m_MTLBuffer()
// PYTHON CODE: print(m)
print(m.extractFirstElement())
}
I stopped short of translating the last two lines of @TeddyHuang-00’s code sample. If I were to perfectly translate what PyTorch is doing there, the script would become absurdly long. The gist:
-
- Make a
MTLBufferwhose raw data isF. This means it’s 4 bytes of memory, set toFloat32(0.0).
- Make a
-
- Copy that
MTLBufferinto a slice ofm, emulating the subscript operator from Python.
- Copy that
-
- Somewhere in the process, the
FMetal buffer becomes anMPSGraphTensorDataand needs to set itsMPSDataType. This may even be a call toMPSGraph.constant, taking anNSDataas its first argument.
- Somewhere in the process, the
-
- In @Hankcs_He’s example, the
MPSDataTypehappened to be.bool. In the @TeddyHuang-00’s example, theMPSDataTypehappened to be.float32. That’s why it doesn’t crash.
- In @Hankcs_He’s example, the
In LLDB, I get the following. I’m appending 0.0 to the output, which would appear if I finished the script. This is similar to the Terminal output quoted above.
T=1.0, F=0.0
-1.0
0.0
Which fallback warning was triggered? I assume it’s a Float64/Double → Float32/Float warning, saying “MPS doesn’t support Double, falling back to Float”. Python floating point numbers are naturally in the FP64 format, which probably causes the warning. Is it possible to set a dtype='float32' parameter to suppress the warning?
It’s especially wierd that MPSGraph.notEqual returns a Float32 tensor, not a Bool tensor. You would think it returns a Bool because it’s comparing two numbers. In the TensorFlow low-level C++ codebase, the operator NotEqual always returns a boolean. Perhaps PyTorch differs from TensorFlow in that regard?
Actually it is not the dtype fallback warning, but a boolean operation one. The full warning message is as follow:
path/to/python3.9/site-packages/torch/_tensor_str.py:103: UserWarning: The operator 'aten::bitwise_and.Tensor_out' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/mps/MPSFallback.mm:11.)
nonzero_finite_vals = torch.masked_select(tensor_view, torch.isfinite(tensor_view) & tensor_view.ne(0))
So… to my naive understanding, this is something that happened implicitly by the torch library during the value assignment process?
Correct. The library implicitly tried to create an MPSGraph tensor or tensor data that was a boolean.
That explains part of the problem for me! Thanks a lot for your hard work and explanation!