Hello Chris, thanks for your detailed reply. I am still not able to reduce the loss with epochs. The Accuracy is starting with 0.5 and is continuously in the dropping & peaking in the range[0.48,0.54].
This is the trend of loss & accuracy I get after multiple iteration of corrections/playing with hyperparams. ( Kindly ingnore the mean test accuracy, not printing any value)
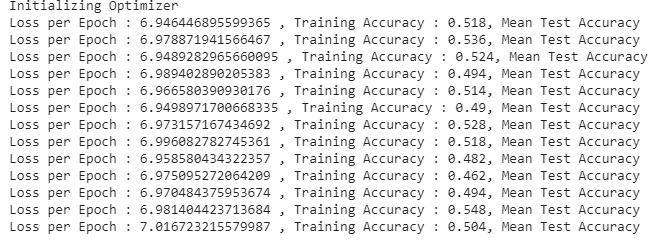
It would be of great help if you could review my entire code and give your inputs on how I could Improve my model.
Below is the entire code
# -*- coding: utf-8 -*-
"""Sentiment_Analysis_Sequence_Classification.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1av8Lcu21Eg6CKm26SCTINm6cDkUhvXW2
Sentiment Analysis is a Sequence Classification Problem. Here The labels are Positive & Negative.
Data Set : https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews?select=IMDB+Dataset.csv
https://gist.github.com/HarshTrivedi/f4e7293e941b17d19058f6fb90ab0fec
"""
import nltk
from nltk.corpus import stopwords
import pandas as pd
import regex as re
from sklearn.model_selection import train_test_split
import plotly.express as px
from nltk.stem.wordnet import WordNetLemmatizer
from pprint import pprint
from collections import Counter
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from torch.nn.utils.rnn import pack_padded_sequence,pad_packed_sequence
import torch.optim as optim
from sklearn.metrics import accuracy_score
# Commented out IPython magic to ensure Python compatibility.
nltk.download(["stopwords","wordnet"])
# %cd /root/nltk_data/corpora/stopwords
stop_Words = stopwords.words("english")
from google.colab import drive
drive.mount('/gdrive')
# Commented out IPython magic to ensure Python compatibility.
# %cd /gdrive/MyDrive/IMDB_Senti_Analysis
!ls
isCuda = torch.cuda.is_available()
if isCuda:
Mydevice = torch.device("cuda")
else:
Mydevice = torch.device("cpu")
main_df = pd.read_csv('IMDB Dataset.csv')
main_df.head()
"""# Split Data"""
## Converting Positive ->1 and negative -> 0
main_df.sentiment[main_df.sentiment=="positive"]=1
main_df.sentiment[main_df.sentiment=="negative"]=0
main_df.head()
main_df["review"][1]
fig = px.bar(main_df,x=["Positive Review","Negative Review"],y = main_df["sentiment"].value_counts(),)
fig.show()
X,Y = main_df["review"].values,main_df["sentiment"].values ## Converting pd.series -> np array
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.9,stratify=Y)
print(X_train.shape,X_test.shape)
"""
---
# Cleaning Data - Tokenization
***
"""
def _string_cleanUp(arrOf_strs):
count=0
listOf_Strs = []
for e_str in arrOf_strs:
e_str = e_str.lower() ## Loawer Casing the entire string
e_str = re.sub(r'<[^>]*>','',e_str) ## Removing HTML Tags
e_str = re.sub(r"[^\w\s]", ' ', e_str) ## Remove Special Characters
e_str = re.sub(r"\d", '', e_str) ## Remove Numbers from string
count+=1
listOf_Strs.append(e_str)
return listOf_Strs
Cleaned_Sentences = _string_cleanUp(X_train)
for e_line in Cleaned_Sentences[0:5]:
print(e_line)
print("\n")
def _token_StringList(StrList,lemObj):
wordList,spl_strs = [],["<sos>","<eos>","<pad>"]
for eLine in StrList:
eLine = eLine.split(" ")
for eWord in eLine:
if eWord in stop_Words:continue ## Skipping stop words
else:
if eWord == '':continue
eWord = lemObj.lemmatize(eWord)
wordList.append(eWord)
return wordList
wl = WordNetLemmatizer()
wordToken = _token_StringList(Cleaned_Sentences,wl)
#wordToken = {ind:word for ind,word in enumerate(spl_strs+wordList)}
wordDict = Counter(wordToken)
print(wordDict)
def _return_most_recurringVocab(worDict):
spl_strs = ["<pad>"]
vList = [x[0] for x in sorted(worDict.items(),key=lambda x:x[1],reverse=True)[:1000]]
return {word:ind for ind,word in enumerate(spl_strs+vList)}
"""# Train & Test Data(Indexed Vocab)"""
trainVocab = _return_most_recurringVocab(wordDict)
print(trainVocab)
## Similar activity for Test Data ##
test_Cleaned_Sentences = _string_cleanUp(X_test)
testWordToken = _token_StringList(test_Cleaned_Sentences,wl)
testVocab = _return_most_recurringVocab(Counter(testWordToken))
print(testVocab)
"""# Custom Data Loader """
## Create a custom dataset loader ##
class _reviews_loader(Dataset):
def __init__(self,X,Y):
super().__init__()
self.X,self.Y = X,Y
def __len__(self):
#d_frame = pd.read_csv(csv_file_name)
return len(self.X)
def __getitem__(self,idx):
returnDict = (self.X[idx],self.Y[idx])
return returnDict
class MyCollateClass():
def __init__(self,vocabDict = None):
self.vocabDict = vocabDict
def _string_cleanUp(arrOf_strs):
count=0
listOf_Strs = []
for e_str in arrOf_strs:
e_str = e_str.lower() ## Loawer Casing the entire string
e_str = re.sub(r'<[^>]*>','',e_str) ## Removing HTML Tags
e_str = re.sub(r"[^\w\s]", ' ', e_str) ## Remove Special Characters
e_str = re.sub(r"\d", '', e_str) ## Remove Numbers from string
count+=1
listOf_Strs.append(e_str)
return listOf_Strs
def _return_indexList(self,OneSentance):
vocabIndexes = []
for eWord in OneSentance.split(" "):
if eWord in list(self.vocabDict.keys()):
vocabIndexes.append(self.vocabDict[eWord])
idx_Tensor = torch.LongTensor(vocabIndexes)
return idx_Tensor
def _stack_Sentance_info(self,max_sentence_len = None,batch_size=None,device='cpu'):
tensorList,updatedTensorList,seqLengths = [],[],[]
for ind,eLine in enumerate(self.cleanedList):
retTensor = self._return_indexList(eLine)
tensorList.append(retTensor)
maxTensorSize = max(list((e_Tensor.size()[0] for e_Tensor in tensorList)))
for e_tensor in tensorList:
seqLengths.append(e_tensor.size()[0])
if e_tensor.size()[0]<maxTensorSize:
diff = maxTensorSize - e_tensor.size()[0]
newTensor = torch.cat([e_tensor,torch.zeros(diff)])
updatedTensorList.append(newTensor)
else:updatedTensorList.append(e_tensor)
finalTensor = torch.stack(updatedTensorList).type(torch.LongTensor).to(device)
return finalTensor,seqLengths
def PadCollate(self,batch):
def _get_max_sentance_len(SentanceList):
return max(list((len(esentance.split(' ')) for esentance in SentanceList)))
def _convert_senti_to_int(SentList,device='cpu'):
sTensor = torch.LongTensor(SentList)
return sTensor
batch_Dict = {}
revList = list((eTuple[0] for eTuple in batch))
sentiList = list((eTuple[1] for eTuple in batch))
stacked_senti_tensor = _convert_senti_to_int(sentiList,device=Mydevice).to(Mydevice)
self.cleanedList = _string_cleanUp(revList)
maxLen_sentance = _get_max_sentance_len(self.cleanedList)
stacked_vocab_tensor,seqLengths = self._stack_Sentance_info(maxLen_sentance,len(batch),device=Mydevice)
batch_Dict = {"Vocab":stacked_vocab_tensor,"Senti":stacked_senti_tensor,"Seqlen":seqLengths}
return batch_Dict
def __call__(self,batch):
return self.PadCollate(batch)
review_dataset = _reviews_loader(X_train,Y_train)
dataloader1 = DataLoader(review_dataset,batch_size = 10,shuffle=True, num_workers=0,collate_fn=MyCollateClass(trainVocab))
for ind,data in enumerate(dataloader1):
if ind>3:break
print(data["Vocab"].device)
print(data["Senti"])
print(data["Vocab"].shape)
print(data["Senti"].shape)
print("seq lenght",data["Seqlen"])
print('*'*75)
"""MODEL
---
"""
class SentiClassify_Model(nn.Module):
def __init__(self,vocabLen,dims,hidden_size,seqLengths,batchSize,numLayers,output_size=2):
super().__init__()
#output_size = 2
self.hidden_size = hidden_size
self.batchSize = batchSize
self.numLayers = numLayers
self.seqLengths = seqLengths
self.embed = nn.Embedding(vocabLen,dims)
self.lstm_cell = nn.LSTM(input_size=dims,hidden_size=hidden_size,batch_first =True,num_layers=self.numLayers)
self.lf = nn.Linear(self.hidden_size*self.numLayers,output_size)
self.F = nn.ReLU(inplace=False)
def forward(self,input,hidden=None,verbose=False):
embeds = self.embed(input).permute(1,0,2)
output,(hidden,cell) = self.lstm_cell(embeds,hidden)
hidden.permute(1,0,2)
linear = self.lf(hidden.view(self.batchSize,-1))
return linear
if verbose:
print("input shape",input.shape)
print('embed shape',embeds.shape)
print("Rehaped output",reshaped_out.size())
print("After Fully conn layer :",lin_output.size())
def init_hiddenlayer(self,num_layers =1,hiddenLayers=1,batch_size=None,device='cpu'):
return (torch.zeros(num_layers*hiddenLayers,batch_size,self.hidden_size,device=device),torch.zeros(num_layers*hiddenLayers,batch_size,self.hidden_size,device=device))
def computeAccuracy(target,source):
sf_max_obj = nn.Softmax(dim=1)
sf_max = sf_max_obj(source)
sf_max = torch.argmax(sf_max,dim=1)
fintensor = torch.where(sf_max==1,1,0) ## 1-> positive ,0->Negative
score = accuracy_score(target.tolist(),fintensor.tolist())
return score
def infer(dataLoader,net,device):
net.eval().to(device)
allScores = []
for ind,data in enumerate(dataLoader):
wordInput,seqLengths,targets = data["Vocab"].permute(1,0),data["Seqlen"],data["Senti"]
source = net(wordInput)
allScores.append(computeAccuracy(targets,source))
return sum/len(allScores)
def _trainLoader(model=None,Train_dataset=None,Test_Loader = None, batchSize =None,vocabList = None,optimm =None,loss_func=None,epochs=1,device='cpu',lr=0.005):
## Hyperparameters ##
dims = 20
hidden_size = 25
num_LSTMLayers = 2
maxLoss = 10000
dataloader1 = DataLoader(Train_dataset,batch_size = batchSize,shuffle=True, num_workers=0,collate_fn=MyCollateClass(vocabList))
loss_per_epoch,train_accuracy,test_accuracy = 0,None,None
## Batch Optimization ##
hidden = None
for i in range(epochs):
cummLoss = 0
for ind,data in enumerate(dataloader1):
wordInput,seqLengths,targets = data["Vocab"].permute(1,0),data["Seqlen"],data["Senti"]
modObj = model(len(vocabList),dims,hidden_size,seqLengths,batchSize,num_LSTMLayers).to(device)
hidden = modObj.init_hiddenlayer(num_layers=num_LSTMLayers, hiddenLayers = 1,batch_size = batchSize,device=device)
#print("ind {}/{}".format(i,hidden[0].size(),hidden[1].size()))
if wordInput.size()[-1]!=batchSize:continue
if optimm==None:
print("Initializing Optimizer")
optimm = optim.Adam(modObj.parameters(),lr=lr)
optimm.zero_grad()
source = modObj(wordInput,hidden)
loss = lossFn(source,targets)
loss.backward()
optimm.step()
cummLoss+=loss.item()*batchSize ## Cumulative loss per batch
train_accuracy = computeAccuracy(targets,source)
loss_per_epoch = cummLoss/batchSize
train_accuracy = computeAccuracy(targets,source)
if loss_per_epoch<maxLoss:
maxLoss = loss_per_epoch
torch.save({
'epoch': i,
'model_state_dict': modObj.state_dict(),
'optimizer_state_dict': optimm.state_dict(),
'loss': loss_per_epoch,
}, "model.pt")
Mean_testAccuracy=0
if Test_Loader!=None:
Mean_testAccuracy = infer(testLoader,modObj,Mydevice)
print("Loss per Epoch : {} , Training Accuracy : {}, Mean Test Accuracy".format(loss_per_epoch,train_accuracy,Mean_testAccuracy))
lossFn = nn.CrossEntropyLoss()
review_dataset = _reviews_loader(X_train,Y_train)
test_data = _reviews_loader(X_test,Y_test)
testLoader = DataLoader(test_data,batch_size = 500,shuffle=True, num_workers=0,collate_fn=MyCollateClass(testVocab))
_trainLoader(model=SentiClassify_Model,Train_dataset=review_dataset,Test_Loader = None,batchSize=500, vocabList = trainVocab,loss_func=lossFn,epochs=20,device=Mydevice)
sample_tens = torch.tensor([[0.45,0.5],
[0.5,0.48]])
print(sample_tens)
bb = torch.argmax(sample_tens,dim=1)
print(bb)
bb = torch.where(bb==1,1,0)
print(bb)
