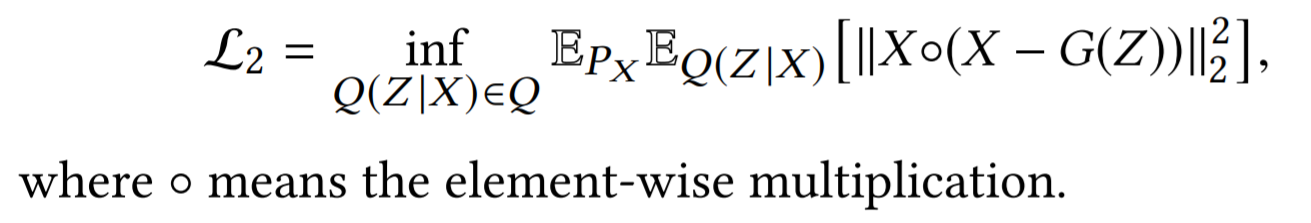
where
Let P_X denote the data distribution, and P_G denotes the encoded training distribution, where Q is the encoders and G is the decoders, X ∼ P_X and Z ∼ Q(Z |X).
Considering the sparsity of the transition matrix P, we focus on non-zero elements in P to speed up our model. we use the transition matrix P as the input feature X. The reconstruction process will make the nodes with similar neighbourhoods have similar latent representations.