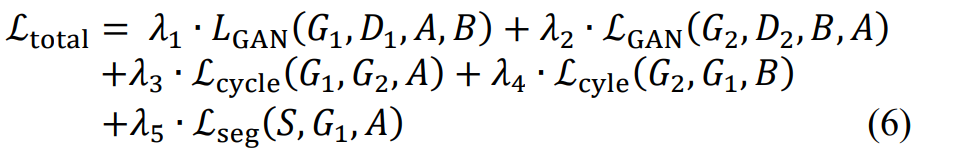The input is fed to Gen network to generate a fake image (fakeA). I use L1 loss to compute the different between input and fakeA. I called it is lossGen.
The fakeA then is fed to the segmentation network to create a predA. I used cross entropy to compute the loss between the label and predA. I called it is lossSeg
For training, I have two way
lossGen=...
lossSeg=...
loss = lossGen + lossSeg
loss.backward()
Both approaches should compute the same gradients.
In the second approach you would need to call lossGen.backward(retain_graph=True), otherwise the intermediate values will be cleared and you’ll get an error calling lossSeg.backward().
However, currently you are using lossSeg to calculate gradients in both models, GenA and SegA.
Is this what you would like to do?
If you would only want to calculate the gradients of lossSeg w.r.t. the parameters in SegA, you should .detach() the output of GenA before passing it so SegA.
Does it really make any differences?
what is the difference if we call it on each loss separately
(i.e. lossGen.backward() and lossSeg.backward()``) comparing to the case that we just doloss.backward()```
No, it won’t make any difference and it might be just my coding style, but I would prefer to handle both losses separately, if they are independent from each other.
Otherwise I would try to figure out, why the author of the code is summing them before calling .backward().
as far as i understand in papers people put all the losses together.
however, in implementation the do it separately.
Similar for the original gan that they put all the losses as a min max loss but in training they do backward first for discriminator and update the weights in discriminator and then do it for generator and update the weights in generator.
also based on my experience it does not really matter if you do backward for each separately comparing to the case that you sum them and then do backward on all of them.