I am currently implementing the following knowledge distillation function:
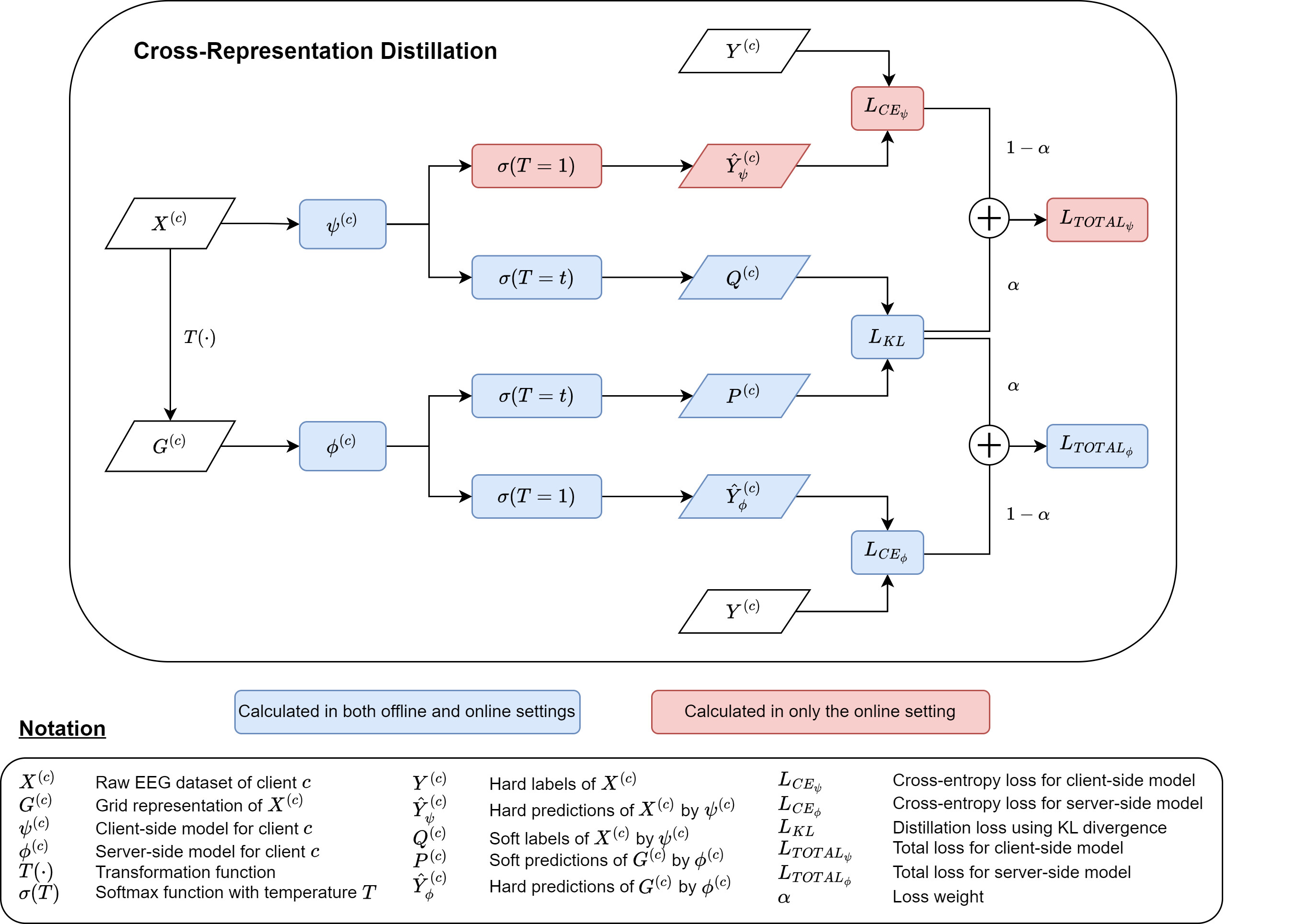
There are two modes:
- Offline mode: only the student model’s parameters are being updated.
- Online mode: both the student and teacher models’ parameters are being updated.
By looking at the figure, the logic should be:
- When
alpha = 0, the accuracy of the student model should be the same regardless of the mode, because it’s only being trained using the hard loss. - When
alpha = 0and the temperature value is changed, the accuracy of the student model should not change. This is becausealpha = 0means no distillation (there should be no influence from the distillation loss).
But my code below doesn’t work as the logic above. I already set the seed with the same value, but the results are still different. Kindly need your help!
Here’s my code for reference:
Code
def train_kd(rnd, epoch, teacher_model, student_model, data_raw, data_grid, lr=0.00001, temperature=1.0, alpha=0.5, mode=‘offline’, seed=None):
if seed is not None:
set_seed(seed)device = torch.device("cuda" if torch.cuda.is_available() else "cpu") criterion_hard = nn.CrossEntropyLoss().to(device) criterion_soft = nn.KLDivLoss(reduction='batchmean').to(device) student_model.to(device) teacher_model.to(device) optimizer_student = optim.Adam(student_model.parameters(), lr=lr) if mode == 'online': optimizer_teacher = optim.Adam(teacher_model.parameters(), lr=lr) student_model.train() if mode == 'online': teacher_model.train() else: teacher_model.eval() running_loss_student = 0.0 running_loss_teacher = 0.0 correct_student = 0 correct_teacher = 0 total = 0 progress_bar = tqdm(enumerate(zip(data_raw, data_grid)), total=len(data_raw), desc=f"Training Round {rnd} | Epoch {epoch+1}", leave=False) for i, (raw, grid) in progress_bar: # Unpacking raw and grid data X_raw, y_raw = raw X_grid, y_grid = grid X_raw, y_raw = X_raw.to(device), y_raw.to(device) X_grid, y_grid = X_grid.to(device), y_grid.to(device) assert torch.equal(y_raw, y_grid), "Both y must be equal" y = y_raw optimizer_student.zero_grad() if mode == 'online': optimizer_teacher.zero_grad() # Forward pass for both models teacher_outputs = teacher_model(X_raw) # Y psi student_outputs = student_model(X_grid) # Y phi # Calculate the hard loss (L_CE) loss_teacher_hard = criterion_hard(teacher_outputs, y) # L_CE psi loss_student_hard = criterion_hard(student_outputs, y) # L_CE phi # Calculate the soft loss (L_KL) loss_soft = criterion_soft( F.log_softmax(student_outputs / temperature, dim=1), # P F.softmax(teacher_outputs / temperature, dim=1) # Q ) # Calculate the combined loss loss_teacher = alpha * loss_soft + (1 - alpha) * loss_teacher_hard # L_TOTAL psi loss_student = alpha * loss_soft + (1 - alpha) * loss_student_hard # L_TOTAL phi # Backward pass for both models if mode == 'online': loss_teacher.backward(retain_graph=True) optimizer_teacher.step() loss_student.backward() optimizer_student.step() running_loss_student += loss_student.item() running_loss_teacher += loss_teacher.item() _, predicted_student = torch.max(student_outputs.data, 1) _, predicted_teacher = torch.max(teacher_outputs.data, 1) total += y.size(0) correct_student += (predicted_student == y).sum().item() correct_teacher += (predicted_teacher == y).sum().item() # Update progress bar current_loss_student = running_loss_student / (i + 1) current_loss_teacher = running_loss_teacher / (i + 1) accuracy_student = 100 * correct_student / total accuracy_teacher = 100 * correct_teacher / total progress_bar.set_postfix(Student_Loss=f'{current_loss_student:.4f}', Student_Accuracy=f'{accuracy_student:.2f}%', Teacher_Loss=f'{current_loss_teacher:.4f}', Teacher_Accuracy=f'{accuracy_teacher:.2f}%') average_loss_student = running_loss_student / len(data_raw) average_loss_teacher = running_loss_teacher / len(data_raw) accuracy_student = 100 * correct_student / total accuracy_teacher = 100 * correct_teacher / total return average_loss_student, average_loss_teacher, accuracy_student, accuracy_teacher