I am trying to implement the methodology proposed in this paper here as the authors have not released the code yet.
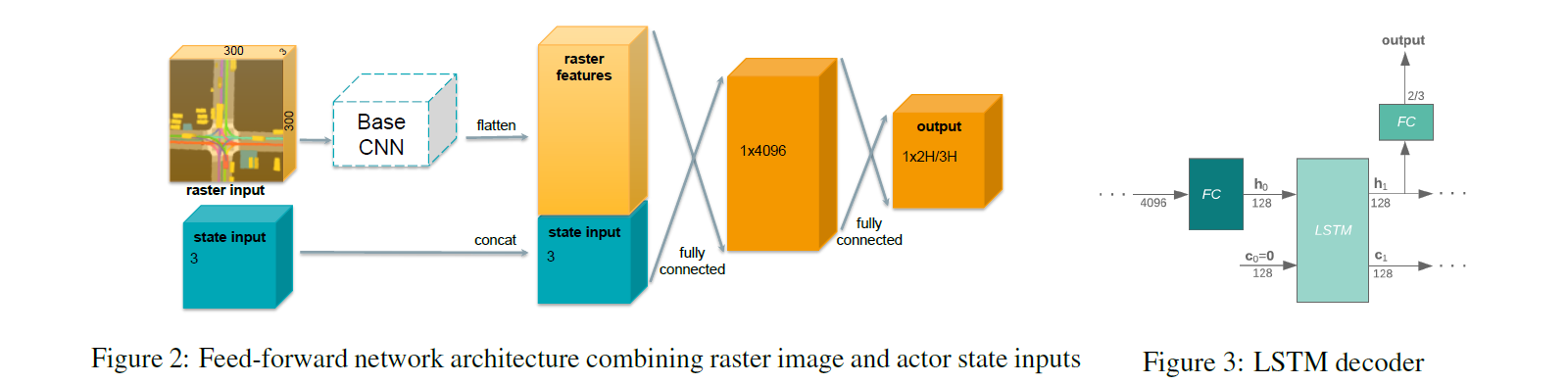
The network architecture is a combination of a BaseCNN and a LSTM layer. The image below depicts the network architecture used by the authors taken from the paper mentioned above.
Considering my input raster size to be [B,3,350,350] with batch_size ‘B’ = 8 and my BaseCNN as mobilenet_v2, the output feature dimension is condensed to [B, 4096] feature vector after the dense layer as per the architecture shown in the above image (Fig 2)
The output of first FC layer is further reduced to [B,128] vector and then given as an input to a LSTM (Fig 3). The initial cell state is initialized to zero. Here is where I am confused on how can I give a 1D vector as an input to LSTM which expects input as (seq_len, batch, input_size) and hidden state of shape (num_layers * num_directions, batch, hidden_size)
PS: Section 3.3 in the paper explains the network architecture in detail.
we train the model to output 2H-D vector, representing predicted x- and y-positions for each of H trajectory point
it seems that the model output is [H, 2H/3H] where H is the no. of trajectory points in the time horizon. So I’d expect the LSTM to receive [H, B, 128] input tensor.
Yes, the LSTM would expect input as [H,B,128]. But the output of the FC layer as can been seen in Fig 3 is of the shape[B,128]. How do I reshape it before feeding it to the LSTM layer ?
As far as I can tell – I only had a very quick look at the paper – the LSTM is used as a decoder similar to Seq2Seq models.
The figure indicates that the output of FC is used as the first initial state which has a shape of (num_layers * num_directions, batch, hidden_size). Given that it’s used as a decoder num_directions=1 and usually num_layers=1 as well. So the expected shape is (1,B,128) So you can simple do unsqueeze(0) on the (B,128) tensor.
However, this clarifies only h_0 and c_0. To get the decoder going also requires some initial input. For decoding texts, that’s usually a special Start-of-Sequence <SOS> token.
Alternatively, the papers state “[…] initial input is obtained by converting output of the FC layer of size 4,096 into a vector of size 128 with another FC layer”. If this really is the input but not the initial hidden state, then they are sloppy with the terminology.
If all fails, just send an email to the authors to clarify. Usually works.