I’m trying to combine multiple related datasets and models into one giant model. Here’s what the architecture looks like:
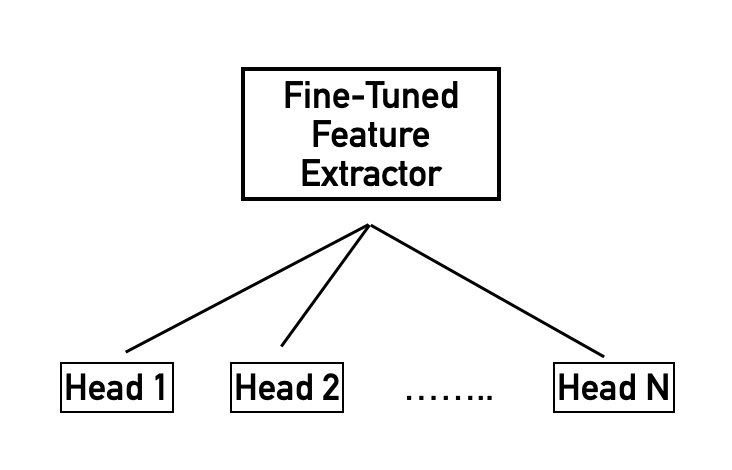
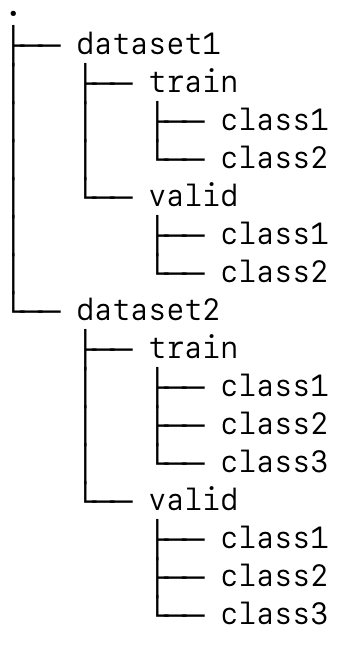
For each head, there’s a dataset with the following structure:
I’ve referred to the following 2 sources for setting up the model, loss, and optimiser:
I’ve setup my model roughly as follows:
class CombinedModel(nn.Module):
def __init__(self):
super(CombinedModel, self).__init__()
self.features = models.mobilenet_v2(pretrained=True)
self.pool = nn.Sequential(*[
nn.AdaptiveAvgPool2d(1),
nn.Flatten(1)
])
self.head1 = nn.Linear(1280,2)
self.head2 = nn.Linear(1280,3)
def forward(x, head_name):
assert head_name in ['head1', 'head2']
x = self.features(x)
# only run the input for the head that is assigned
# to that dataset
return getattr(self, head_name)(x)
What I’d like to do is a round-robin style training where I train one batch from one dataset, fine-tune the respective head and the feature extractor’s parameters, then do another batch from another dataset, and so on.
I’ve setup individual loss functions for each head and a single optimiser for all of them. I’ve checked that the optimiser only calculates gradients for the head_name that is passed in while calling the forward method.
optimiser = optim.Adam([
{'params': model.features[-5:].parameters(), 'lr':1e-5},
*[{'params':getattr(model,head).parameters(), 'lr':1e-3}
for head in ['head1', 'head2']
])
criterions = {
'head1': nn.CrossEntropyLoss(),
'head2': nn.CrossEntropyLoss()
}
I can create a dataset for the respective head with torchvision.datasets.ImageFolder but am unclear on how to combine it for multiple datasets since I’d like to switch between datasets after every batch.
I’d imagined the training loop to look something like this:
model = CombinedModel()
# training mode
# each batch should switch (randomly) between
# head1 and head2
for input,labels,head_name in dataloaders:
# head_name == 'head1' or 'head2'
optimiser.zero_grad()
outputs = model(inputs, head_name)
# calculate loss for respective head
loss = criterions[head_name](outputs, labels)
loss.backward()
optimiser.step()
I’d love any input on what would be the right way to implement this.
Thank you for your time!