I have corresponding text and images that have a label too between 1-9. Using transfer learning on BERT (size 768), I dropped text feature vectors. Using transfer learning on top of ResNet50 I dropped image feature vectors (size 2048).
How can I design a transfer learning network (or another reasonable network) that combines these feature vectors? Which network should be used for this?
I have a 5 fold experiment and I have test and train txt files that on each line contains the corresponding feature vectors.
Say, for test set belonging to fold 0 I have the following two text files:
fold0_test_resnet_9class.txt
fold0_test_BERT_9class.txt
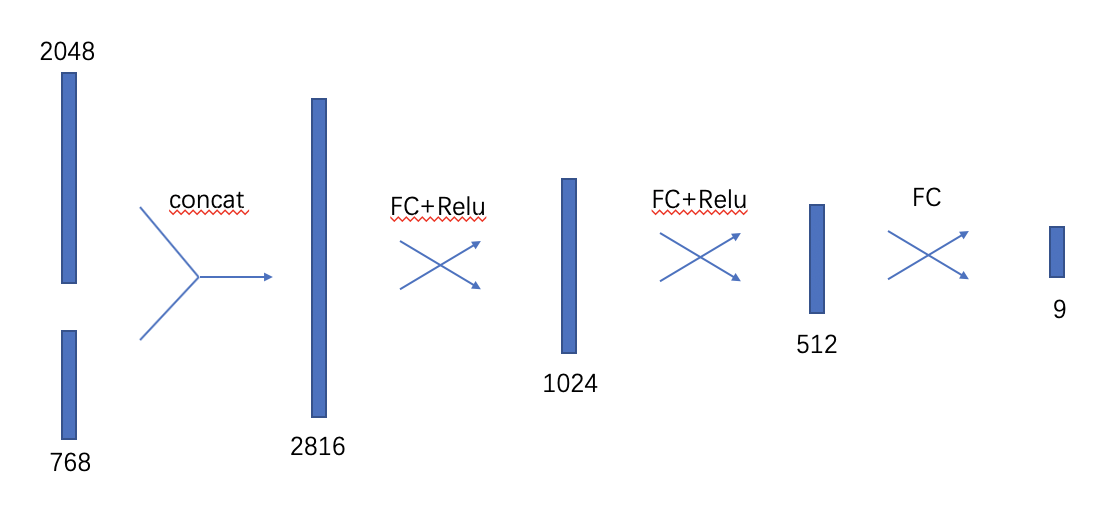
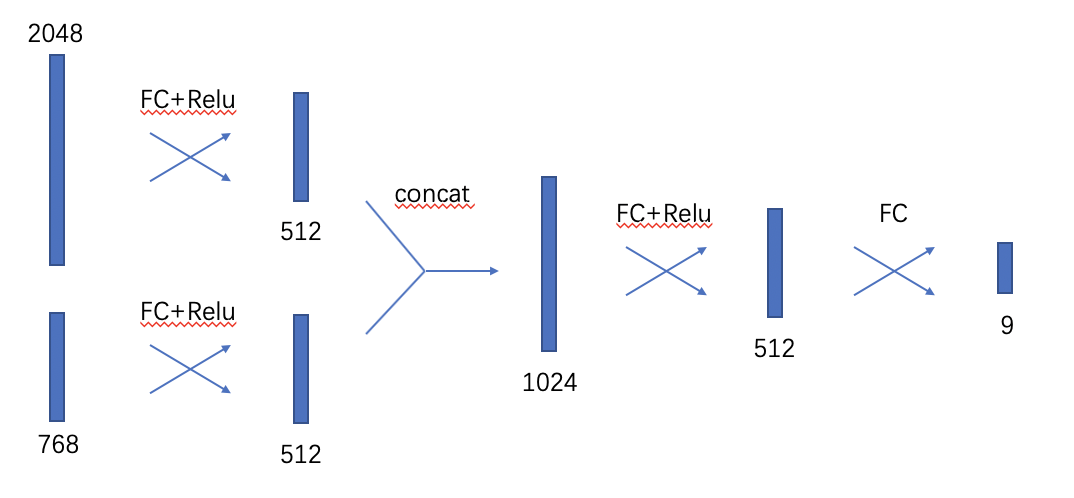
I’m working together with Mona_Jalal and we’ve tried two different methods for now. The first is to concatenate the two features together and then adding fully connected layers to make the prediction. The second is to first use fully connected layers to make the two features of the same length, and then concatenate the vectors and make the prediction.
I’ve included the code and ideas below and found that they have similar accuracy. Does anyone know the difference between the two? And if there are any other methods for feature combination? Thanks!
Could you try to use these features separately first and check the performance of the models?
Also, could you check the feature statistics (mean, min, max) of both feature sets?
After this I would compare the “single feature models” with the combined one and check, if the performance differs a lot or if the combined model might just learn from one feature while ignoring the other.
If you have the feeling (I’m not sure how to check it mathematically other then maybe low weights for the ignored feature) that this might be the case, I would try to add some normalization layers before combining the features, so that the range will be at least closer to each other.
Also, a good baseline using these combined features might be an XGBoost model to compare against (if you can use other methods besides neural networks).
Thank you so much for your help! I’ve actually tested the features separately. For Bert, I have an accuracy of 84.42%, and for ResNet, I have an accuracy of 65.58%. After combining them, I have an accuracy of 84.42% for method1 and 84.57% for method2. Does this mean that the images do not actually help during prediction? Thanks!
Yes, exactly.
If the statistics differ a lot for both feature sets, the parameters might not be able to get useful information from both inputs.
It’s similar to passing a normalized image after training on unnormalized ones (in [0, 255]).
The normalized image might just “look” like a black image to the model.
I am facing a similar problem. Can you please suggest any examples of normalization layers/code that I can use so that the features from both the models are in a comparable range?
Unfortunately, I don’t know which normalization layer would work the best (and you should certainly try different approaches) or if even a manual scaling would work fine.