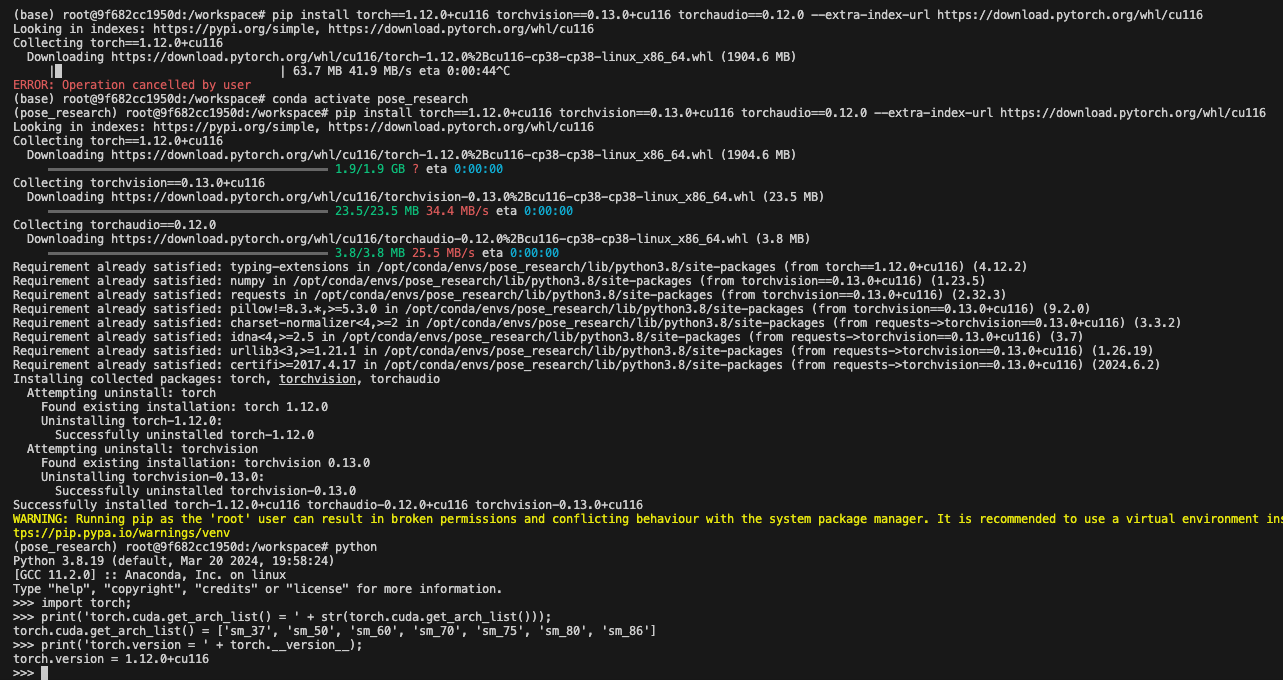
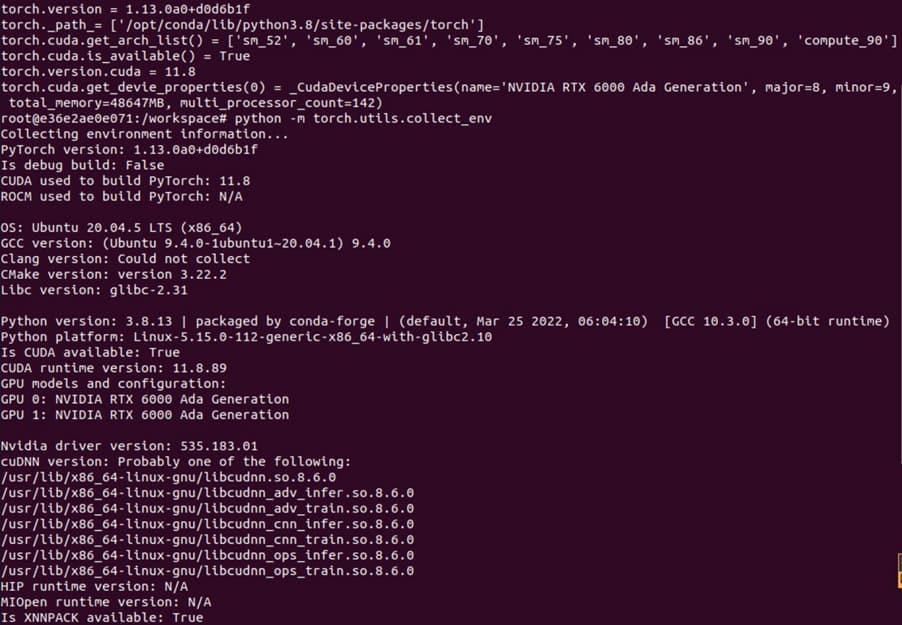
Among the following variables:
- GPU device arch (e.g. RTX 6000 Ada) and compute capability (sm_89 for Ada)
- GPU driver version and CUDA driver version
- CUDA runtime version
- PyTorch version
The first 2 are not supposed to change in our context. If we can determine the minimum required CUDA runtime version (bullet 3), we can determine PyTorch version (bullet 4) accordingly. So what is the minimum/earliest CUDA runtime version which supports our GPU (RTX 6000)?
The following evidences seem to conclude that it is CUDA 11.8:
-
Nvidia CUDA 11.8 release notes: “This release introduces support for both the Hopper and Ada Lovelace GPU families.”
-
CUDA wiki: The first CUDA version supporting Ada Lovelace is CUDA 11.8.
-
Nvidia Framework Support Matrix for NGC PyTorch containers: The first/earliest version of NGC PyTorch container supporting Ada Lovelace architecture is v22.10. In this container, PyTorch (v1.13) was built on CUDA 11.8 (on Ubuntu 20.04).
Without resorting to compiling PyTorch from source, we have the following options:
- Use NGC PyTorch container 22.10 or newer
- Use a PyTorch binary distribution: the minimum PyTorch binary version supporting CUDA 11.8 is PyTorch 2.0.0 (see the list below)
1.13.0+cpu, 1.13.0+cu116, 1.13.0+cu117, 1.13.0+cu117.with.pypi.cudnn, 1.13.0+rocm5.1.1, 1.13.0+rocm5.2, 1.13.1, 1.13.1+cpu, 1.13.1+cu116, 1.13.1+cu117, 1.13.1+cu117.with.pypi.cudnn, 1.13.1+rocm5.1.1, 1.13.1+rocm5.2, 2.0.0, 2.0.0+cpu, 2.0.0+cpu.cxx11.abi, 2.0.0+cu117, 2.0.0+cu117.with.pypi.cudnn, 2.0.0+cu118, 2.0.0+rocm5.3, 2.0.0+rocm5.4.2, 2.0.1, 2.0.1+cpu, 2.0.1+cpu.cxx11.abi, 2.0.1+cu117, 2.0.1+cu117.with.pypi.cudnn, 2.0.1+cu118, 2.0.1+rocm5.3, 2.0.1+rocm5.4.2, 2.1.0, 2.1.0+cpu, 2.1.0+cpu.cxx11.abi, 2.1.0+cu118, 2.1.0+cu121, 2.1.0+cu121.with.pypi.cudnn, 2.1.0+rocm5.5, 2.1.0+rocm5.6, 2.1.1, 2.1.1+cpu, 2.1.1+cpu.cxx11.abi, 2.1.1+cu118, 2.1.1+cu121, 2.1.1+cu121.with.pypi.cudnn, 2.1.1+rocm5.5, 2.1.1+rocm5.6, 2.1.2, 2.1.2+cpu, 2.1.2+cpu.cxx11.abi, 2.1.2+cu118, 2.1.2+cu121, 2.1.2+cu121.with.pypi.cudnn, 2.1.2+rocm5.5, 2.1.2+rocm5.6, 2.2.0, 2.2.0+cpu, 2.2.0+cpu.cxx11.abi, 2.2.0+cu118, 2.2.0+cu121, 2.2.0+rocm5.6, 2.2.0+rocm5.7, 2.2.1, 2.2.1+cpu, 2.2.1+cpu.cxx11.abi, 2.2.1+cu118, 2.2.1+cu121, 2.2.1+rocm5.6, 2.2.1+rocm5.7, 2.2.2, 2.2.2+cpu, 2.2.2+cpu.cxx11.abi, 2.2.2+cu118, 2.2.2+cu121, 2.2.2+rocm5.6, 2.2.2+rocm5.7, 2.3.0, 2.3.0+cpu, 2.3.0+cpu.cxx11.abi, 2.3.0+cu118, 2.3.0+cu121, 2.3.0+rocm5.7, 2.3.0+rocm6.0, 2.3.1, 2.3.1+cpu, 2.3.1+cpu.cxx11.abi, 2.3.1+cu118, 2.3.1+cu121, 2.3.1+rocm5.7, 2.3.1+rocm6.0)
- Any flaw in the above analysis and conclusion?
- Is there any other option short of compiling PyTorch from source?