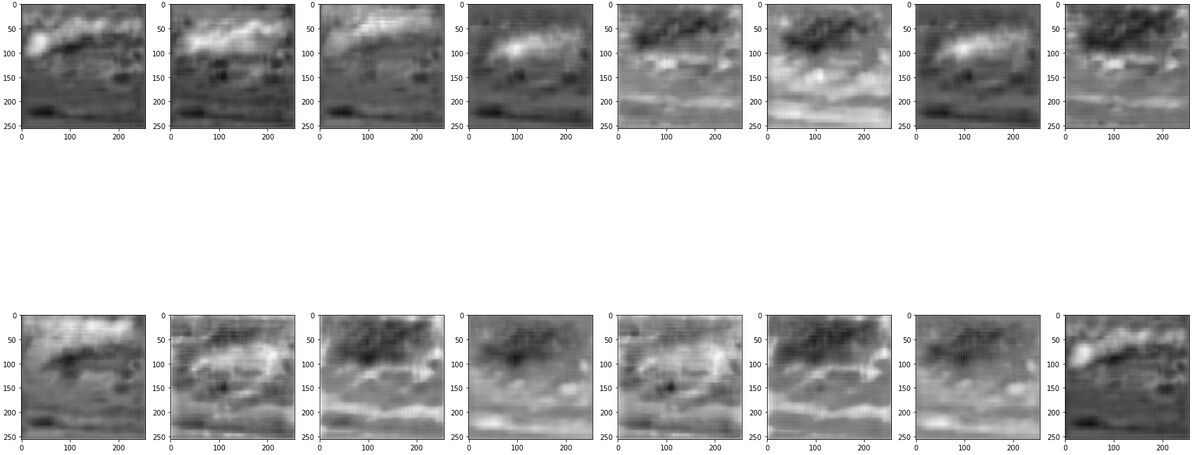
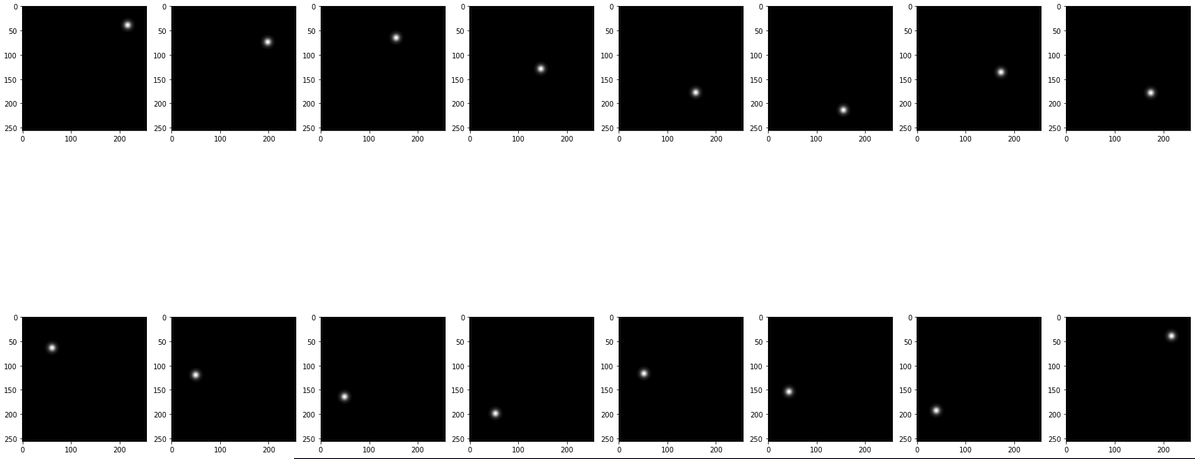
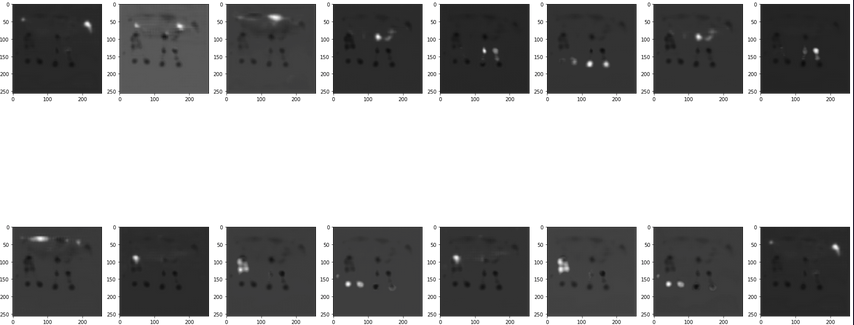
- Hi I am using using a network that produces an output heatmap (torch.rand(1,16,1,256,256)) with
Softmax( ) as the last network activation. - I want to compute the MSE loss between the output heatmap and a target heatmap.
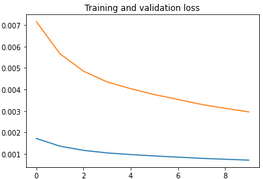
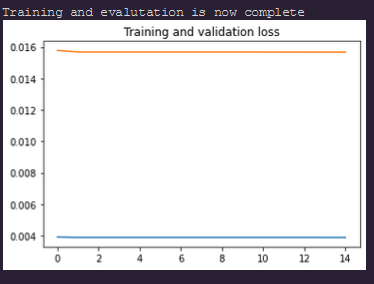
- When I add the softmax the network loss doesn’t decrease and is around the same point and works when I remove the softmax.
How can I go about computing mse loss by using softmax()?
Thanks
from torch.nn import init
class NET(torch.nn.Module):
def __init__(self):
super(NET, self).__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Conv3d(3, 64, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=64),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(64, 128, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(2,2,2),stride=(2,2,2)),
torch.nn.Conv3d(128, 256, kernel_size=(3,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool3d(kernel_size=(1,2,2),stride=(1,2,2)),
torch.nn.Conv3d(256, 512, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=512),
torch.nn.ReLU(inplace=True),
)
self.decoder = torch.nn.Sequential(
torch.nn.ConvTranspose3d(512, 256, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1), output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(256, 256, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=256),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(256,128, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.Conv3d(128, 128, kernel_size=(1,3,3), stride=(1,1,1), padding=(1,1,1)),
torch.nn.BatchNorm3d(num_features=128),
torch.nn.ReLU(inplace=True),
torch.nn.ConvTranspose3d(128,16, kernel_size=(1,3,3), stride = (1,2,2), padding=(1,1,1),output_padding=(0,1,1)),
)
def forward(self, image):
encoder = self.encoder(image)
decoder = self.decoder(encoder)
return torch.nn.Softmax(dim=1)(decoder)