Hey Frank,
I tried to use the softmax in the last layer with the MSE loss. The model predictions and ground truth look a bit similar to what the prediction was from the last post using the loss function you suggested to me.
Model predictions
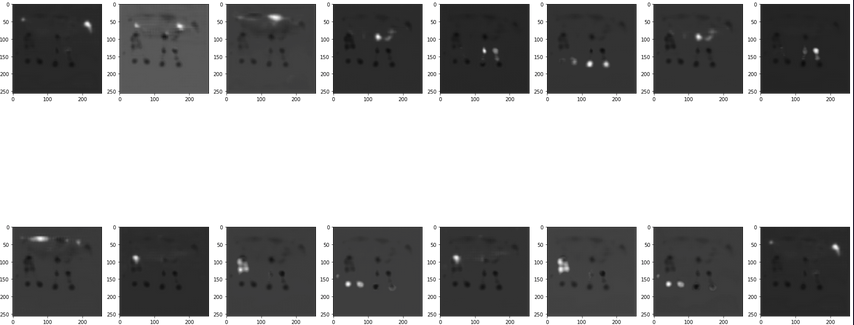
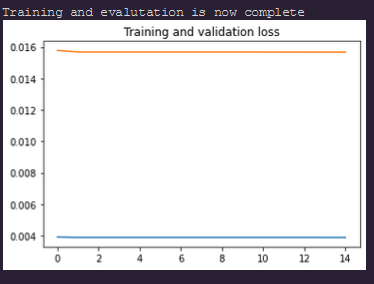
They look quite close compared to the target but then I end up with the problem of the loss not going down. The loss you suggested is not helping the model learn the heatmaps somehow but the loss goes down in value. In the ref paper, they mention that softmax was applied as a softmax transformation together with MSE loss. Not sure what that means.
Do you think there might be something that is missing or else I could try? The loss is being compared with the probability of the key points present in each heatmap to the gaussian distribution over a point in a particular location in the confidence/heat map