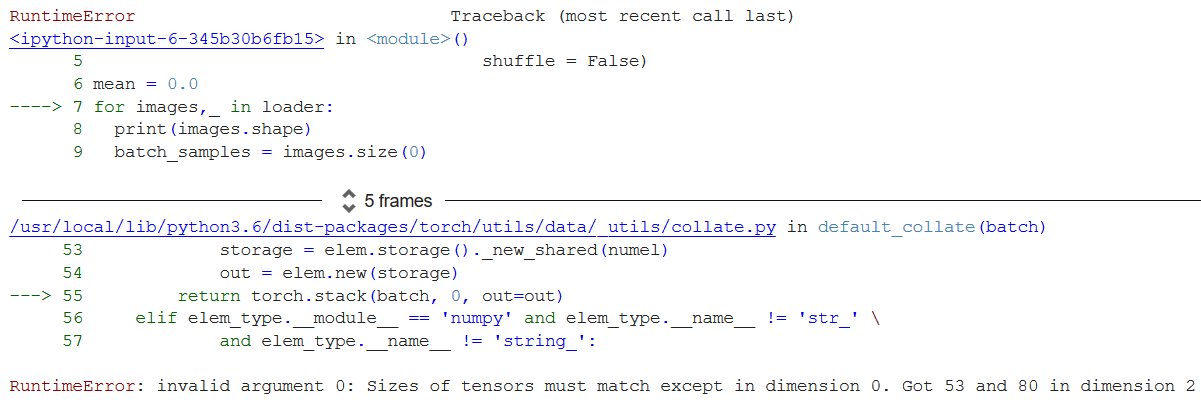
Hello. So I am trying to compute the mean and the standard deviation per channel of my train dataset (three-channel images of different shapes).
For the mean I can do it in two ways, but I get slightly different results.
import torch
from torchvision import datasets, transforms
dataset = datasets.ImageFolder('train',
transform=transforms.ToTensor())
First computation:
mean = 0.0
for img, _ in dataset:
#mean += img.sum([1,2])/torch.numel(img[0])
mean += img.mean([1,2])
mean = mean/len(dataset)
print(mean)
# tensor([0.3749, 0.3992, 0.4505])
Second computation:
sumel = 0.0
countel = 0
for img, _ in dataset:
sumel += img.sum([1, 2])
countel += torch.numel(img[0])
mean = sumel/countel
print(mean)
# tensor([0.3802, 0.4003, 0.4513])
Any idea why there is this small difference in the two computations?
Similarly for the std
sumel = 0.0
countel = 0
for img, _ in dataset:
img = (img - mean.unsqueeze(1).unsqueeze(1))**2
sumel += img.sum([1, 2])
countel += torch.numel(img[0])
std = torch.sqrt(sumel/countel)
Is it a correct way to compute it?