I am trying to do a activity recognition. For that i have a lot of small videos to train my network. Each video has a different size in length. So i create for every video a new dataset and put them together with the ConcatDataset function, to avoid “jumps” when i would just load it as one big video or dataset. Now when i run my network with num_workers = 0 it works perfectly fine, but when i put num_workers to 1 or higher i get the following error:
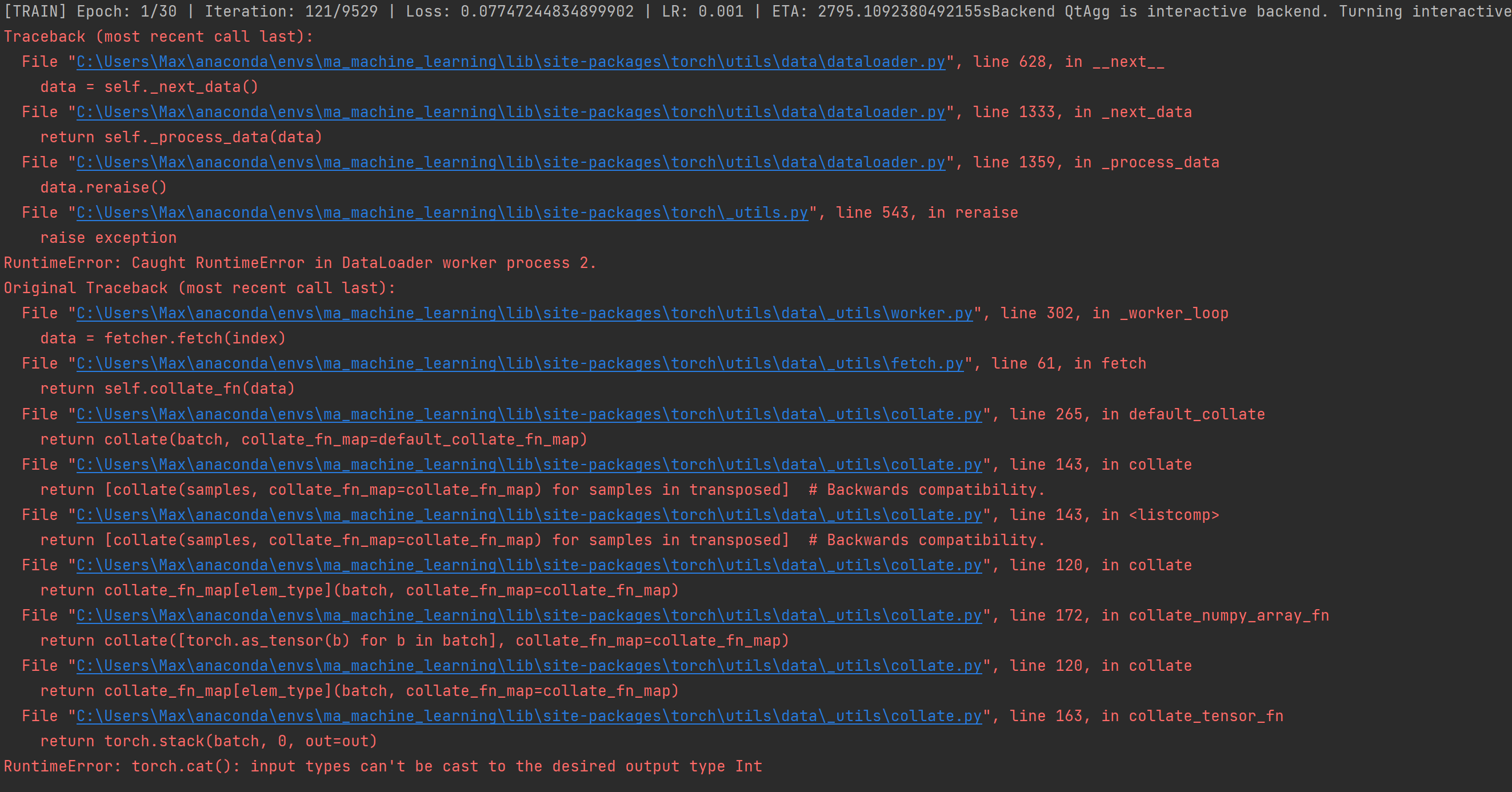
The problem occurs in the dataloader while iterating. When i change the batch_size to a higher or lower value, the code will run for 1 or 2 epochs until the same error occurs.
I checked all my batches for the input data type and they have exactly the same type. For input a float and output a int32. I am running the code on windows and on a cuda device.
My custom dataset looks like this:
class HandPoseDatasetNumpy(Dataset):
def init(self, data, distances=Config.only_dist):
self.data = data
self.distances = distances
def __len__(self):
return len(self.data[0])
def __getitem__(self, idx):
x = self.data[0]
y = self.data[1]
seq_x = x[idx:idx + Config.sequence_length:Config.sequence_steps]
seq_y = y[idx:idx + Config.sequence_length:Config.sequence_steps]
# ergänzt weitere zahlen für die sequenz damit diese nicht in das neue video springt
to_pad = math.ceil(Config.sequence_length/Config.sequence_steps) - seq_x.shape[0]
x_pad = np.pad(seq_x, ((0, to_pad), (0, 0)), mode='mean')
y_pad = np.pad(seq_y, ((0, to_pad), (0, 0)), mode='mean')
x = x_pad.reshape(math.ceil(Config.sequence_length/Config.sequence_steps), 21, 3)
return x, y_pad
If you have any ideas or need more information, just tell me`
The error message and description sounds a bit weird so I’m unsure if the DataLoader is really failing in the mentioned line of code or just re-raises a previous error.
Could you add some debug print statements into the collate.py file right before the torch.stack operation is called and check what batch contains?
@J_Johnson I am using windows, do you remember how you solved it?
@ptrblck batches look fine to me, containing my desired batches
the error message gets created in the worker.py when trying fetcher.fetch(index)
try:
data = fetcher.fetch(index)
except Exception as e:
if isinstance(e, StopIteration) and dataset_kind == _DatasetKind.Iterable:
data = _IterableDatasetStopIteration(worker_id)
# Set `iteration_end`
# (1) to save future `next(...)` calls, and
# (2) to avoid sending multiple `_IterableDatasetStopIteration`s.
iteration_end = True
else:
# It is important that we don't store exc_info in a variable.
# `ExceptionWrapper` does the correct thing.
# See NOTE [ Python Traceback Reference Cycle Problem ]
data = ExceptionWrapper(
where="in DataLoader worker process {}".format(worker_id))
The problem is, when I am in debug mode at the iteration where the error occurs and create a test_data via
def my_own_collate_fn(batch):
data = np.array([item[0] for item in batch])
target = np.array([item[1] for item in batch])
target = torch.from_numpy(target).long()
data = torch.from_numpy(data).float()
return [data, target]
Now it works without an error, but I am not to sure if the new function uses all num_workers
The collate_fn is applied after the workers have loaded all samples of the batch, so it should not decrease or block any workers.
It’s still strange to see that your custom collate_fn fixed it. Were you able to inspect the batch created the failure?