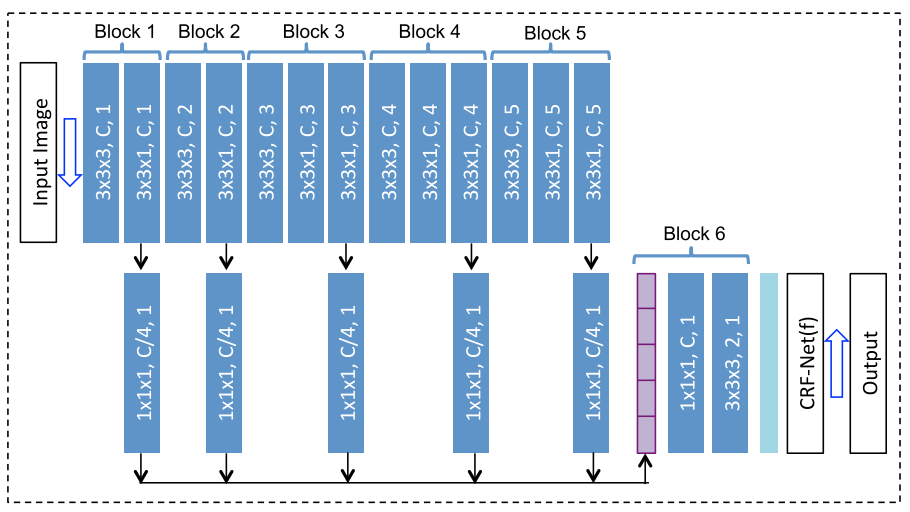
I contacted the author but did not receive an answer sadly. Currently I have the problem that the model is not learning. When given random input the prediction and the loss is always the same. I implemented the P-Net once with upsampling and once with padding. Neither does learn.
Any idea why it does not learn?
Version with upsampling:
class P_Net(nn.Module):
def __init__(self, in_channels=2, out_channels=16, deep_supervision=False): # or out_channels = 16/64
super(P_Net, self).__init__()
self.do_ds = False
self.block1 = nn.Sequential(
nn.Conv3d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1), # or kernel_size=[3, 3, 3]
nn.ReLU(),
)
self.block2 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=2),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=2), # or kernel_size=[3, 3, 3]
nn.ReLU(),
)
self.block3 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3),
nn.ReLU(),
)
self.block4 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4),
nn.ReLU(),
)
self.block5 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5),
nn.ReLU(),
)
self.block6 = nn.Sequential(
nn.Conv3d(in_channels=int(out_channels/4)*5, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=2, kernel_size=3, stride=1, padding=0, dilation=1),
# nn.ReLU(),
)
self.compress1 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress2 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress3 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress4 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress5 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.upsample1 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
self.upsample2 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
self.upsample3 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
self.upsample4 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
self.upsample5 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
self.upsample6 = nn.Upsample(size=[96, 160, 160], mode='trilinear')
def forward(self, x):
x = self.block1(x)
compress1 = self.compress1(x)
x = self.block2(x)
compress2 = self.compress2(x)
x = self.block3(x)
compress3 = self.compress3(x)
x = self.block4(x)
compress4 = self.compress4(x)
x = self.block5(x)
compress5 = self.compress5(x)
compress1 = self.upsample1(compress1)
compress2 = self.upsample2(compress2)
compress3 = self.upsample3(compress3)
compress4 = self.upsample4(compress4)
compress5 = self.upsample5(compress5)
x = torch.cat((compress1, compress2, compress3, compress4, compress5), dim=1)
x = self.block6(x)
x = self.upsample6(x)
return x
Version with padding:
class P_Net(nn.Module):
def __init__(self, in_channels=2, out_channels=16, deep_supervision=False): # or out_channels = 16/64
super(P_Net, self).__init__()
self.do_ds = False
self.block1 = nn.Sequential(
nn.Conv3d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1), # or kernel_size=[3, 3, 3]
nn.ReLU(),
)
self.block2 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=2),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=2), # or kernel_size=[3, 3, 3]
nn.ReLU(),
)
self.block3 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=3),
nn.ReLU(),
)
self.block4 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=4),
nn.ReLU(),
)
self.block5 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5),
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=5),
nn.ReLU(),
)
self.block6 = nn.Sequential(
nn.Conv3d(in_channels=int(out_channels/4)*5, out_channels=out_channels, kernel_size=3, stride=1, padding=0, dilation=1), # or kernel_size=[3, 3, 1]
nn.ReLU(),
nn.Conv3d(in_channels=out_channels, out_channels=2, kernel_size=3, stride=1, padding=0, dilation=1),
# nn.ReLU(),
)
self.compress1 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress2 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress3 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress4 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.compress5 = nn.Sequential(
nn.Conv3d(in_channels=out_channels, out_channels=int(out_channels/4), kernel_size=1, stride=1, padding=0, dilation=1),
nn.ReLU(),
)
self.pad1 = nn.ReplicationPad3d((2, 2, 2, 2, 2, 2))
self.pad2 = nn.ReplicationPad3d((4, 4, 4, 4, 4, 4))
self.pad3 = nn.ReplicationPad3d((9, 9, 9, 9, 9, 9))
self.pad4 = nn.ReplicationPad3d((12, 12, 12, 12, 12, 12))
self.pad5 = nn.ReplicationPad3d((15, 15, 15, 15, 15, 15))
self.pad6 = nn.ReplicationPad3d((2, 2, 2, 2, 2, 2))
def forward(self, x):
x = self.block1(x)
x = self.pad1(x)
compress1 = self.compress1(x)
x = self.block2(x)
x = self.pad2(x)
compress2 = self.compress2(x)
x = self.block3(x)
x = self.pad3(x)
compress3 = self.compress3(x)
x = self.block4(x)
x = self.pad4(x)
compress4 = self.compress4(x)
x = self.block5(x)
x = self.pad5(x)
compress5 = self.compress5(x)
x = torch.cat((compress1, compress2, compress3, compress4, compress5), dim=1)
x = self.block6(x)
x = self.pad6(x)
return x
For training I use the following test code:
import torch
import torch.nn as nn
model = P_Net()
model = model.to("cuda:5")
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.BCEWithLogitsLoss()
model.train()
while True:
input = torch.rand((1, 2, 96, 160, 160)).to("cuda:5")
label = torch.rand((1, 2, 96, 160, 160)).to("cuda:5")
prediction = model(input)
loss = criterion(prediction, label)
optimizer.zero_grad()
loss.backward()