How I can feed two pytorch models with different data, then concatenate the output of the two models before prediction.
You could basically write the model in the same way you’ve described it:
out1 = model1(in1)
out2 = model2(in2)
out = torch.cat((out1, out2), dim=1)
pred = classifier(out)
Thanks for your response. I’m still confused. This is what I did, But I’m stuck in point number 3:
1- I created two models (BERTClassA, BERTClassB), and detatch the classifier layers from them.
2- Then I concatenated the output from the two models in train function.
3- Then How I can loop through each data loader and pass each one to the models, then taking the output back from two models and concatenate it, after that pass it to the ensamble class.
Data
training_loader1 = DataLoader(training_set2, **train_params)
training_loader2 = DataLoader(training_set2, **train_params)
Model A
class BERTClassA(torch.nn.Module):
def init(self):
super(BERTClassB, self).init()
self.l1 = BertModel.from_pretrained(“bert-base-uncased”)
self.pre_classifier = torch.nn.Linear(768, 768)
self.dropout = torch.nn.Dropout(.3)
def forward(self, input_ids, attention_mask):
output_1 = self.l1(input_ids=input_ids, attention_mask=attention_mask)
hidden_state = output_1[0]
pooler = hidden_state[:, 0]
pooler = self.pre_classifier(pooler)
pooler = torch.nn.ReLU()(pooler)
pooler = self.dropout(pooler)
return output
Model B
class BERTClassB(torch.nn.Module):
def init(self):
super(BERTClassB, self).init()
self.l1 = BertModel.from_pretrained(“bert-base-uncased”)
self.pre_classifier = torch.nn.Linear(768, 768)
self.dropout = torch.nn.Dropout(.3)
def forward(self, input_ids, attention_mask):
output_1 = self.l1(input_ids=input_ids, attention_mask=attention_mask)
hidden_state = output_1[0]
pooler = hidden_state[:, 0]
pooler = self.pre_classifier(pooler)
pooler = torch.nn.ReLU()(pooler)
pooler = self.dropout(pooler)
return output
Train function
def train(epoch):
tr_loss = 0
n_correct = 0
nb_tr_steps = 0
nb_tr_examples = 0
model.train()
for _,data1 in enumerate(training_loader1 , 0):
for _,data2 in enumerate(training_loader2 , 0):
ids = data1['ids'].to(device, dtype = torch.long)
mask = data1['mask'].to(device, dtype = torch.long)
targets1 = data1['targets'].to(device, dtype = torch.long)
ids2 = data2['ids'].to(device, dtype = torch.long)
mask2 = data2['mask'].to(device, dtype = torch.long)
targets2 = data2['targets'].to(device, dtype = torch.long)
outputs1 = modelBERT(ids, mask)
outputs2 = modelBERT2(ids2, mask2)
outputs = torch.cat((outputs1, outputs2), dim=1)
ensamble_output = model(outputs)
loss = loss_function(ensamble_output, targets1)
tr_loss += loss.item()
big_val, big_idx = torch.max(ensamble_output.data, dim=1)
n_correct += calcuate_accu(big_idx, targets1)
nb_tr_steps += 1
nb_tr_examples+=targets1.size(0)
if _%100==0:
loss_step = tr_loss/nb_tr_steps
accu_step = (n_correct*100)/nb_tr_examples
print(f"Training Loss per 100 steps: {loss_step}")
print(f"Training Accuracy per 100 steps: {accu_step}")
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'The Total Accuracy for Epoch {epoch}: {(n_correct*100)/nb_tr_examples}')
epoch_loss = tr_loss/nb_tr_steps
epoch_accu = (n_correct*100)/nb_tr_examples
print(f"Training Loss Epoch: {epoch_loss}")
print(f"Training Accuracy Epoch: {epoch_accu}")
return
for epoch in range(EPOCHS):
train(epoch)
Ensamble function
class MyEnsemble(torch.nn.Module):
def init(self, modelA, modelB):
super(MyEnsemble, self).init()
self.modelA = modelA
self.modelB = modelB
self.classifier = torch.nn.Linear(768, 3)
def forward(self, x1, x2):
x1 = self.modelA(x1)
x2 = self.modelB(x2)
x = torch.cat((x1, x2), dim=1)
x = self.classifier(F.relu(x))
return x
modelA = BERTClass()
modelB = BERTClassB()
model = MyEnsemble(modelA, modelB)
model.to(device)
I assume you would like to pass batches from training_loader1 as x1 and batches from training_loader2 as x2 to the model. If so, you could either iterate both loaders via zip or load the batches manually via:
iter_loader1 = iter(training_loader1)
batch1 = next(iter_loader1)
...
Thanks a lot Ptrblck. Your answer worked with me.
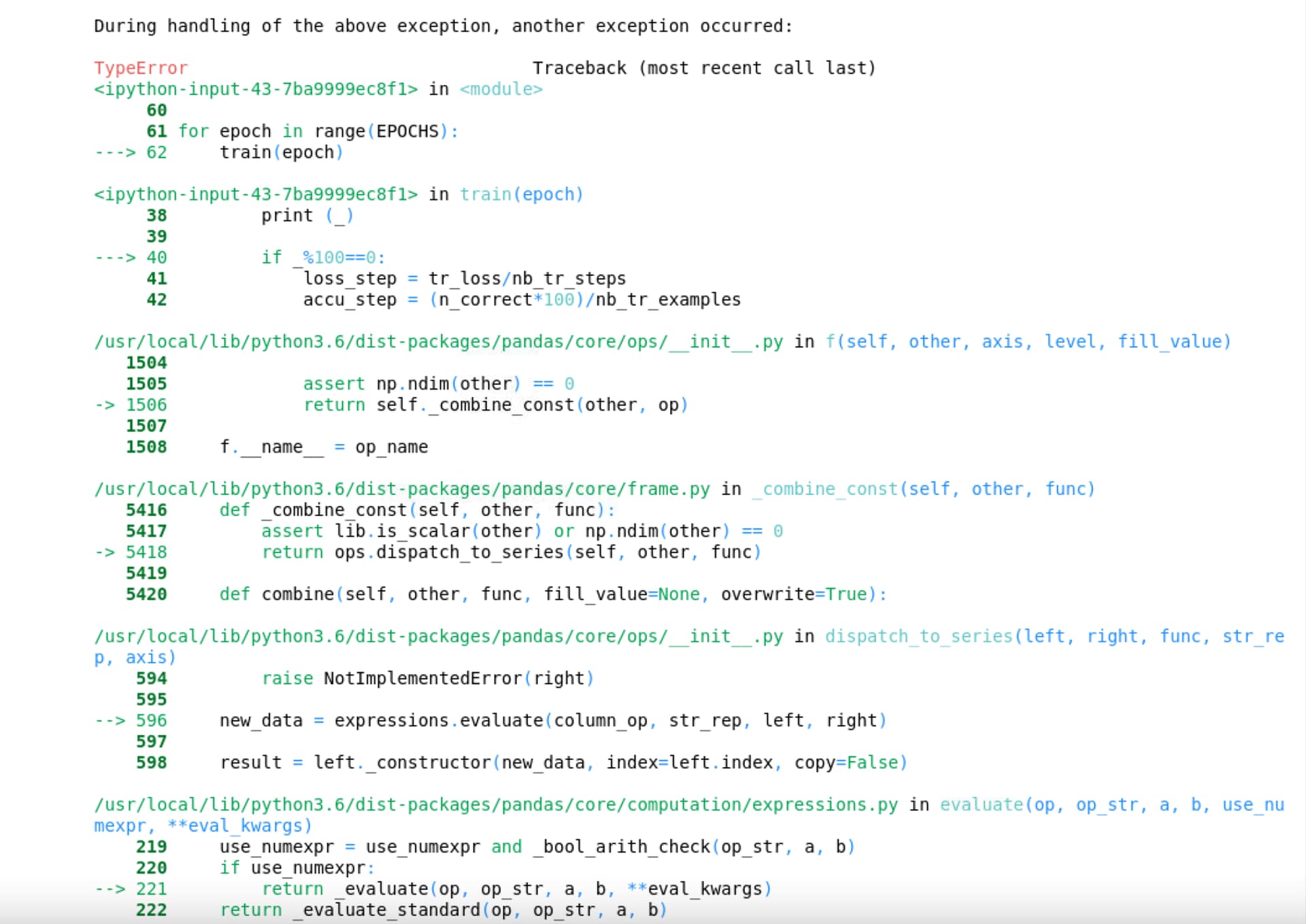
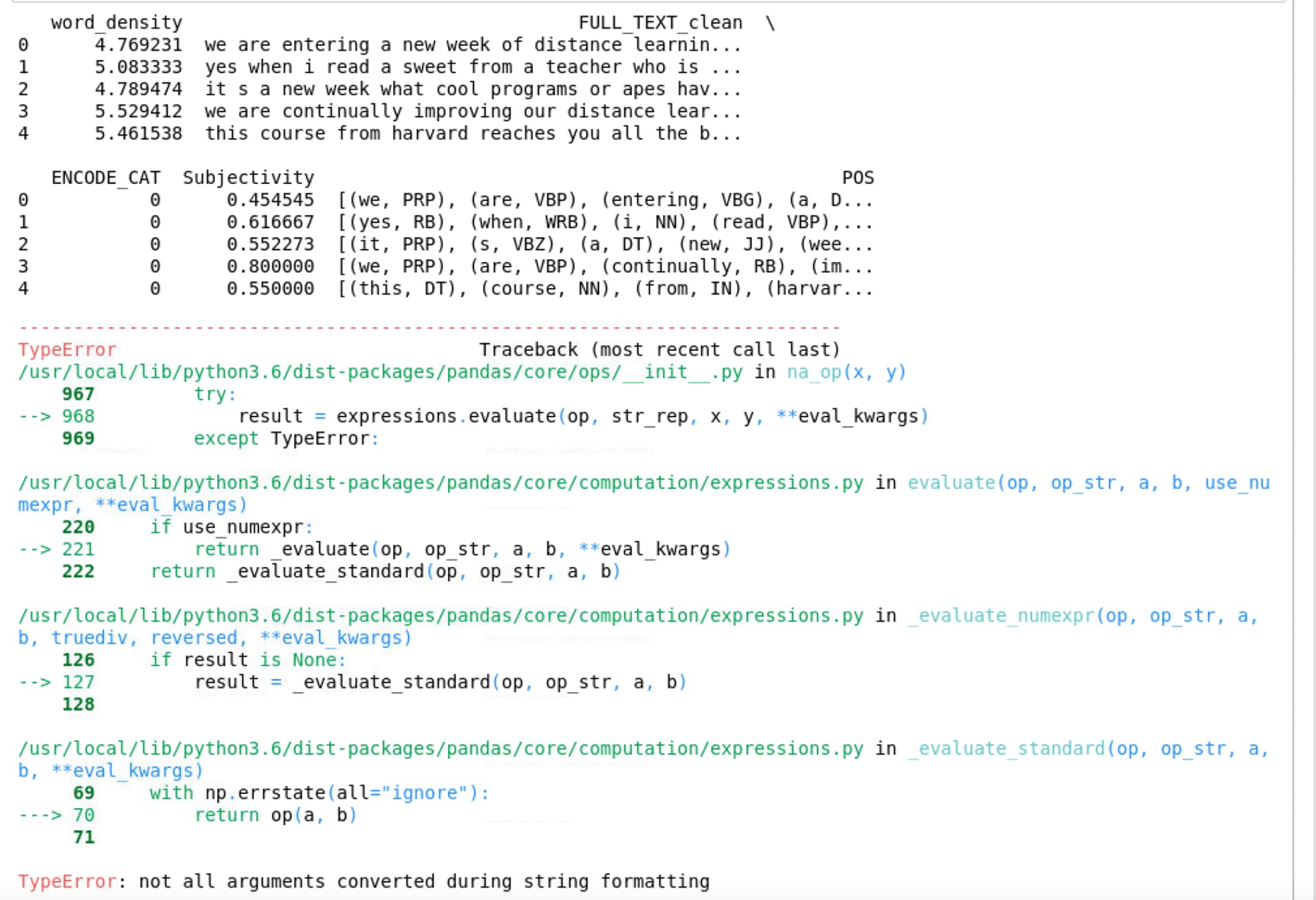
Please help me with this error
TypeError: not all arguments converted during string formatting
Training function
for i in range(TRAIN_BATCH_SIZE):
iter_loader1 = iter(training_loader1)
batch1 = next(iter_loader1)
iter_loader2 = iter(training_loader2)
batch2 = next(iter_loader2)
ids1 = batch1['ids'].to(device, dtype = torch.long)
mask1 = batch1['mask'].to(device, dtype = torch.long)
targets1 = batch1['targets'].to(device, dtype = torch.long)
ids2 = batch2['ids'].to(device, dtype = torch.long)
mask2 = batch2['mask'].to(device, dtype = torch.long)
targets2 = batch2['targets'].to(device, dtype = torch.long)
outputs = model(ids1, mask1, ids2, mask2)
print(outputs)
loss = loss_function(outputs, targets2)
print(loss)
tr_loss += loss.item()
print(tr_loss)
big_val, big_idx = torch.max(outputs.data, dim=1)
print(big_val, big_idx)
n_correct += calcuate_accu(big_idx, targets2)
nb_tr_steps += 1
print(nb_tr_steps)
nb_tr_examples+=targets2.size(0)
print(nb_tr_examples)
#print (_)
if _%100==0:
loss_step = tr_loss/nb_tr_steps
accu_step = (n_correct*100)/nb_tr_examples
print(f"Training Loss per 100 steps: {loss_step}")
print(f"Training Accuracy per 100 steps: {accu_step}")
optimizer.zero_grad()
loss.backward()
# # When using GPU
optimizer.step()
print(f'The Total Accuracy for Epoch {epoch}: {(n_correct*100)/nb_tr_examples}')
epoch_loss = tr_loss/nb_tr_steps
epoch_accu = (n_correct*100)/nb_tr_examples
print(f"Training Loss Epoch: {epoch_loss}")
print(f"Training Accuracy Epoch: {epoch_accu}")
return
The new error is raised by pandas and I don’t know which line of code is causing the issue.
My guess would be pandas might be used for some preprocessing, which might fail?

The _ might refer to the last return value in this case, wouldn’t it?
Change the _ to an explicit variable which tracks the iterations and it should work.
Thanks a lot Ptrblck… your answers very helpful