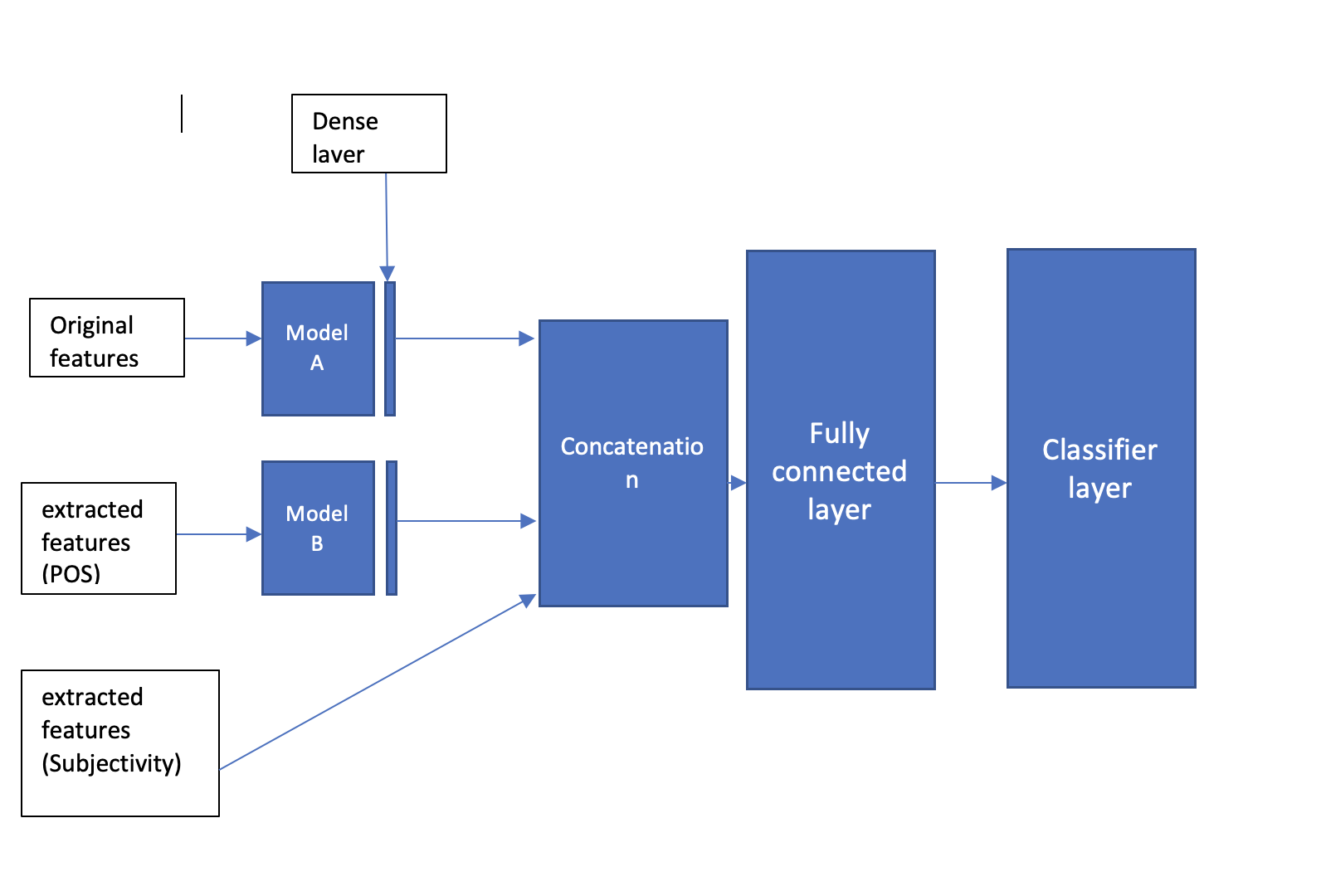
I have model A, which is BERT, and model B, which is also BERT. Each model has different input features.
I removed the classifier layer from each model before constructing a parent model in which I will perform concatenation for three distinct features:
-The output of model A (text)
-The output of model B (POS)
-And other features (subjectivity)
Then I will make it input to the fully connected layer and make the classification
The architecture will be like this
the problem is that the loss too high 218 and the accuracy not improved compared to the results before adding the new features which is not input to any model…
I think I should do normalization but I don’t know how…
This is the parent model:
class ParentModel(torch.nn.Module):
def __init__(self, modelA, modelB):
super(ParentModel, self).__init__()
self.modelA = modelA
self.modelB = modelB
self.fc1 = torch.nn.Linear(2560, 1536)
self.classifier = torch.nn.Linear(1536, 3)
def forward(self, x1, x2, x3, x4, x5, x6):
x11 = self.modelA(x1, x2)
x22 = self.modelB(x3, x4)
x = torch.cat((x11, x22, x5, x6), dim=1)
x = torch.nn.ReLU()(self.fc1(x))
x = self.classifier(x)
return x
ids1 = batch1[‘ids’].to(device, dtype = torch.long)
mask1 = batch1[‘mask’].to(device, dtype = torch.long)
targets1 = batch1[‘targets’].to(device, dtype = torch.long)
ids2 = batch2[‘ids’].to(device, dtype = torch.long)
mask2 = batch2[‘mask’].to(device, dtype = torch.long)
ids3 = batch3[‘ids’].to(device, dtype = torch.long)
mask3 = batch3[‘mask’].to(device, dtype = torch.long)
outputs = model(ids1, mask1, ids2, mask2, ids3, mask3)
Please advise if the problem is not related to the normalization issue.
this is the results:
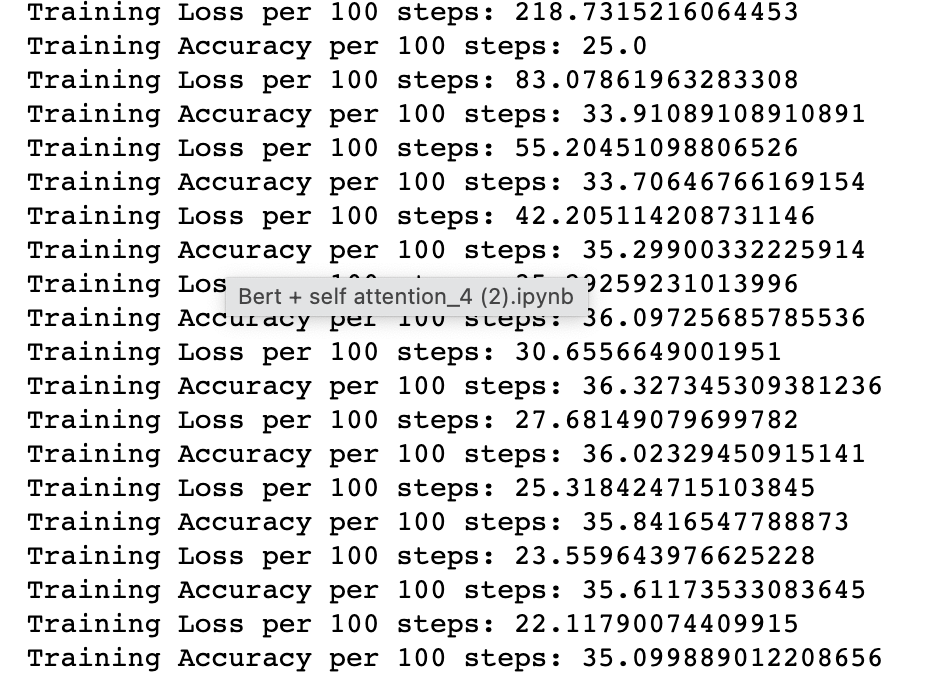
The results for concatenating just the output of model A and model B is:

